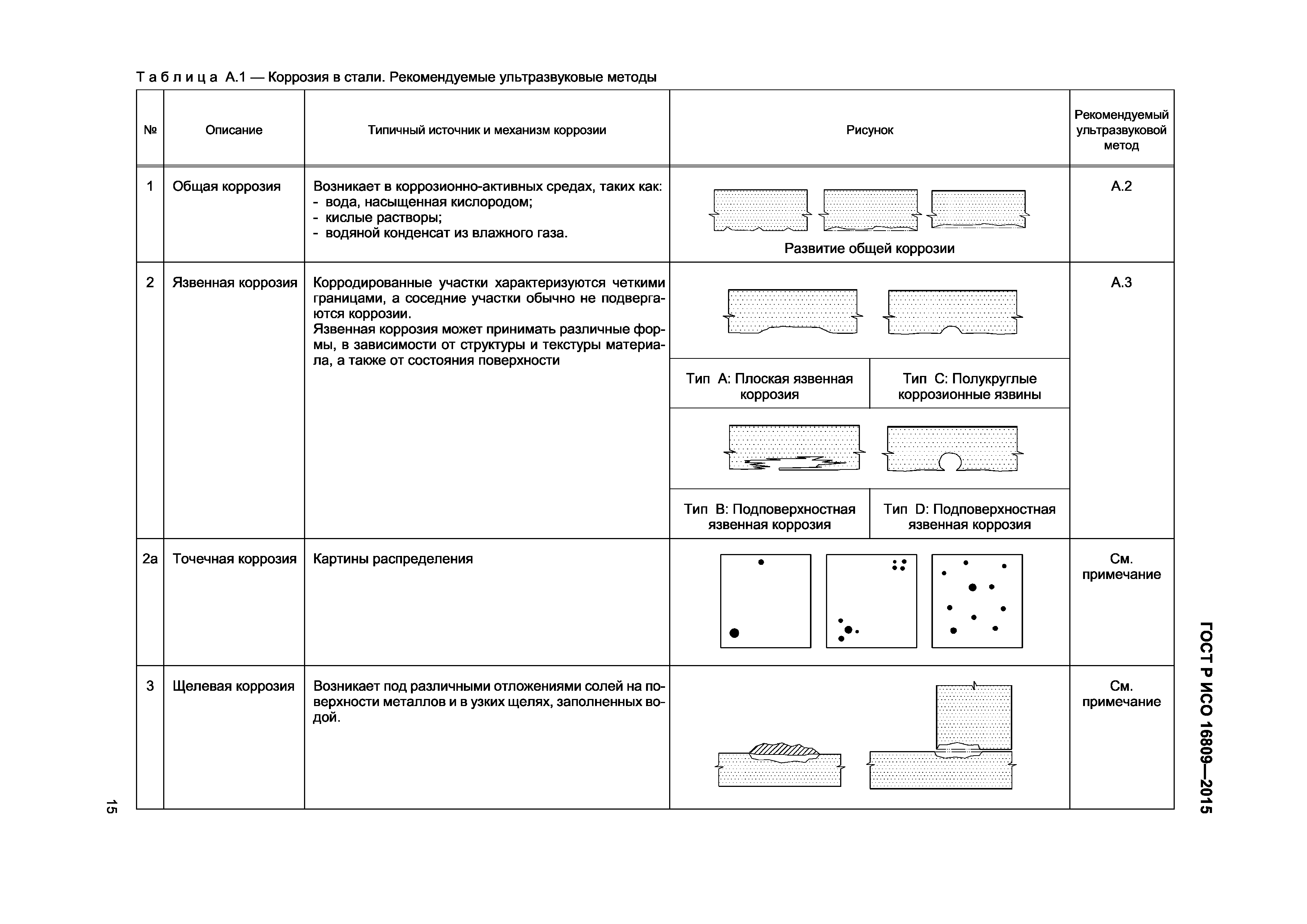
Ультразвуковой контроль (УЗК) — Аттестационный центр «НАКС-Иваново»
Лаборатория НАКС-Иваново осуществляет работу по ультразвуковому контролю — одному из самых популярных методов неразрушающего контроля, использующему для выявления дефектов материалов и сварных швов ультразвуковые волны путём излучения и принятия ультразвуковых колебаний, отраженных от внутренних несплошностей (дефектов) с дальнейшим анализом их амплитуды, времени прихода, формы и других характеристик с помощью специального оборудования — ультразвукового дефектоскопа.
Ультразвуковой контроль предназначен для выявления в сварных швах и околошовной зоне трещин, непроваров, несплавлений, пор, шлаковых включений, расслоений и других видов дефектов без расшифровки их характера, но с указанием координат, условных размеров и количества обнаруженных дефектов.
Ультразвуковое исследование не разрушает и не повреждает исследуемый образец, что является его главным преимуществом. Можно проводить контроль изделий из разнообразных материалов, как металлов, так и неметаллов.
Ультразвуковой контроль сварных швов
Сварные швы являются самой массовой областью применения ультразвуковой дефектоскопии. Это достигается за счёт мобильности ультразвуковой установки, высокой производительности контроля, высокой точности, высокой чувствительности к любым внутренним (объёмным — поры, металлические и неметаллические включения; плоскостным — непровары, трещины), а также внешним, т.е. поверхностным дефектам сварных швов (подрезы, несоответствия валика усиления и т.п.).
Многие ведомственные документы подразумевают обязательный ультразвуковой контроль сварных швов, либо альтернативный выбор ультразвукового или радиационного контроля, либо контроль обоими методами.
Ультразвуковой контроль сварных соединений является эффективным способом выявления дефектов сварных швов и металлических изделий, залегающих на глубинах от 1-2 миллиметров до 6-10 метров.
Ультразвуковой контроль сварных соединений проводится по ГОСТ 14782-86 «Контроль неразрушающий. Соединения сварные. Методы ультразвуковые» и позволяет осуществлять ультразвуковую диагностику качества сварных соединений, выявлять и документировать участки повышенного содержания дефектов, классифицируя их по типам и размерам. Для разных типов сварных соединений применяются соответствующие методики ультразвукового контроля.
Ультразвуковой контроль сварных соединений позволяет провести полную диагностику сварных соединений без использования дорогостоящих методов неразрушающего контроля качества сварных швов, таких как рентгенографический, гаммаграфический, магнитопорошковый или капиллярный.
| Лидеры продаж УКШаблон Красовского УШК-1 Эталоны чувствительности канавочные Магнитный прижим П-образный Термометр testo 905-T2
|
 Принцип действия ПЭП основан на пьезоэлектрическом эффекте – явлении возникновения электрической поляризации под действием механических напряжений.
Принцип действия ПЭП основан на пьезоэлектрическом эффекте – явлении возникновения электрической поляризации под действием механических напряжений.

 д.
д. Наклонные РС ПЭП с продольной волной применяют для контроля соединений с крупнозернистой структурой и высоким уровнем шумов (аустенитные швы).
Наклонные РС ПЭП с продольной волной применяют для контроля соединений с крупнозернистой структурой и высоким уровнем шумов (аустенитные швы).
 Толщина контролируемых П 112 объектов, как правило, находится в диапазоне от 1 до 30мм. Характеристики П112 приведены в таблице:
Толщина контролируемых П 112 объектов, как правило, находится в диапазоне от 1 до 30мм. Характеристики П112 приведены в таблице: Преобразователи П121 позволяют выявлять трещины, объемные дефекты, такие как неметаллические включения, поры, непровары, усадочные раковины и т.п. С помощью преобразователей типа П121, как правило, определяются характеристики вертикально ориентированных дефектов. Характеристики и возможная маркировка П 121 одного из производителей приведены в таблице:
Преобразователи П121 позволяют выявлять трещины, объемные дефекты, такие как неметаллические включения, поры, непровары, усадочные раковины и т.п. С помощью преобразователей типа П121, как правило, определяются характеристики вертикально ориентированных дефектов. Характеристики и возможная маркировка П 121 одного из производителей приведены в таблице: с толщиной стенки от 2 до 6 мм., используются контактные раздельно-совмещенные хордовые преобразователи. Применение преобразователей хордового типа особенно эффективно для контроля тонкостенных сварных швов от 2 до 4 мм.
с толщиной стенки от 2 до 6 мм., используются контактные раздельно-совмещенные хордовые преобразователи. Применение преобразователей хордового типа особенно эффективно для контроля тонкостенных сварных швов от 2 до 4 мм.
 А так же Республики Казахстан, Белоруссия и другие страны СНГ.
А так же Республики Казахстан, Белоруссия и другие страны СНГ.Что такое ОЗК, расшифровка и порядок одевания защитного костюма
ОЗК расшифровывается как «общевойсковой защитный костюм», он разработан в 1984 году и активно эксплуатируется по нынешний день.
ОЗК обладает высоким уровнем защиты от радиационной пыли, биохимического оружия. В то же время позволяет сохранить достаточно высокую мобильность носителя костюма.
Использование таких костюмов актуально во времена, когда ведётся борьба с короновирусом. Для дезинфекции необходимо пользоваться услугами специально обученных людей, которые проведут дезинфекцию дезинфицирующими средствами широкого спектра действия, но безвредными для человека и животных. Через 5 минут после дезинфекции вы можете пользоваться помещением.
Для дезинфекции необходимо пользоваться услугами специально обученных людей, которые проведут дезинфекцию дезинфицирующими средствами широкого спектра действия, но безвредными для человека и животных. Через 5 минут после дезинфекции вы можете пользоваться помещением.
Обыкновенно ОЗК носится с каким-либо СИЗОД (средством индивидуальной защиты органов дыхания) — например, противогазом.
Далее в статье вы узнаете что такое ОЗК, что входит в комплект и как расшифровывается, как правильно его надевать и каково предназначение общевойскового защитного комплекта в армии, промышленности и других сферах.
Назначение костюма
ОЗК — комплексный общевойсковой защитный костюм, обеспечивающий высокую степень индивидуальной защиты от радиации и биохимических факторов, сохранность дыхательных путей и кожи человека, а также его снаряжения, одежды, оружия и прочей экипировки.
В случае заблаговременной экипировки ОЗК действие отрицательных факторов на снаряжение ослабляется, также повышается уровень защиты дыхательных путей и кожи носителя.
Сферы применения общевойскового защитного комплекта
Можно выделить четыре основные сферы использования, в порядке убывания это:
- Вооружённые силы Российской Федерации: снаряжение личного состава для проведения операций на загрязнённой или потенциально загрязнённой территории.
- Рыбалка, реже охота, некоторые виды любительского туризма: превосходная защита от дождя, грязи, повышенной влажности.
- Заводы, лаборатории и промышленные предприятия: снаряжение для собственных специалистов на случай необходимости ликвидации последствий химической или биологической аварии.
- Некоторые милитаризованные игры — страйкбол, хардбол, лазертаг и им подобные.
Помимо этого ОЗК (расшифровка — общевойсковой защитный комплект) может использоваться для фотосессий, тематического декора помещений и во многих иных сферах, но значительно реже. ОЗК популярен среди гражданского населения (особенно в России и некоторых странах ближнего зарубежья) благодаря своей водонепроницаемости и долговечности.
Устройство, размеры, варианты комплектации
Из чего состоит защитный костюм ОЗК и какие виды химзащиты бывают? В состав ОЗК входят плащ, перчатки, чулки, чехол/чехлы для всего комплекта или же компонентов по отдельности, а также детали, способствующие более плотному прилеганию костюма к телу. Реже ОЗК дополнительно укомплектовывается пилоткой с козырьками и наушниками.
Подробнее о каждом элементе:
- Плащ производят из специально разработанного прорезиненного материала, который защищает от различных вредных воздействий (радиация, бактериологические и химические вещества). Застёгивается на шпеньки.Манжеты рукавов на резинке, капюшон регулируется кулиской. Есть карман для хранения запасных деталей, он расположен на рукаве, слева. Плащ оснащён дополнительными застёжками, с помощью которых модифицируется в комбинезон.Размер плаща подбирается под рост человека.Таблица соотношения ростовки и размера:
Рост, см Размер До 165 1 От 166 до 170 2 От 171 до 175 3 От 176 до 180 4 От 181 5 Масса плаща чуть больше полутора килограммов.

- Чехол изготавливается из обычной ткани без добавления резины. Он используется как для хранения комплекта, так и для оперативного надевания — плащ можно носить под чехлом как заспинный рюкзак, а по специальной команде распустить лямки, не снимая конструкцию. Скатанный плащ расправится, и останется только надеть рукава и застегнуться.
- Перчатки-краги исполнены из того же прорезиненного материала. Выпускается в двух вариантах — летнем БЛ-1М и зимнем Б3-1М. У летних перчаток по пять пальцев, у зимних — три (для большого и указательного отдельные, для остальных трёх пальцев общее).
Зимний вариант утеплён изнутри, утепляющие вкладыши вынимаются. Перчатки-краги в положении «наготове» хранят в тканевом чехле и носят на поясе. Перчатки (и зимние, и летние) имеют общий размер. Масса одной пары перчаток — около 350 граммов. - Защитные чулки из прорезиненного материала. Надеваются прямо на обувь. Крепятся к поясному ремню, фиксируются несколькими закрепками на стопе. Подошва выполнена из другого материала, обладающего теми же защитными свойствами, но более прочного. В набор защитных чулок входят сами чулки, 6 шпеньков и 2 прорезиненные ленты для крепления на пояс.Размерный ряд чулок:
Размер обуви Размер чулок 37-40 1 41-42 2 43 и более 3 Масса пары чулок 0,9— 1,3 кг.
- Пилотка — не обязательный компонент. Представляет собой шапку из прорезиненного материала с удлинёнными деталями в области ушей для их защиты, козырьком спереди и козырьком сзади для прикрытия шеи.

 Подошва выполнена из другого материала, обладающего теми же защитными свойствами, но более прочного. В набор защитных чулок входят сами чулки, 6 шпеньков и 2 прорезиненные ленты для крепления на пояс.Размерный ряд чулок:
Подошва выполнена из другого материала, обладающего теми же защитными свойствами, но более прочного. В набор защитных чулок входят сами чулки, 6 шпеньков и 2 прорезиненные ленты для крепления на пояс.Размерный ряд чулок:Как определить качество и отсутствие брака при покупке
Для того, чтобы выбрать качественный ОЗК, необходимо провести тщательную визуальную проверку всего устройства.
Стоит обратить особое внимание на места стыков деталей плаща, рукавов, проверить наличие всех шпеньков, тесёмок, а также целостность хлястиков.
Наличие талька на внешней стороне плаща говорит либо о его новизне, либо о повторной обработке тальком. Следует присмотреться к местам продевания шпеньков — если они разработаны и легко пропускают шпенёк, то этот комбинезон неоднократно использовался.
Предлагаем посмотреть еще фото защитного костюма ОЗК:
Как правильно одевать (видео), норматив надевания
По инструкции, военные обязаны надевать костюм в двух случаях:
- по команде «Газы!»;
- по собственной инициативе при обнаружении признаков заражения территории того или иного типа.
Смотрите видео о том, как правильно одеть ОЗК (костюм химической и биологической защиты):
Порядок одевания ОЗК:
- Чулки: надеть поверх собственной обуви, прикрепить к ремню, потуже зафиксировать на голенях.
- Непосредственно плащ: накидывается вместе с рукавами, застёгивается.
- Противогаз: в соответствии с правилами надевания противогаза.
- Капюшон плаща и/или защитная пилотка: козырьки и «наушники» пилотки должны быть направлены вниз, капюшон фиксируется кулиской.
- Перчатки: надеть на руки, спрятать манжеты перчаток под рукава.

Нормативы одевания ОЗК (время и оценка):
| Затраченное время, мин:сек | Оценка |
| 4:00 | Отлично |
| 4:20 | Хорошо |
| 5:00 | Удовлетворительно |
Снятие костюма возможно только в том случае, если достоверно установлено отсутствие опасности для человека — либо это незаражённая территория, либо очищенная территория, отсутствие опасности которой подтверждено приборами.
Долгое ношение оказывает утомительное воздействие на организм, в связи с этим необходимо не носить их дольше времени, предписанного нормативами.
В зависимости от температуры окружающей среды это может быть как 16 минут максимум (при температуре выше 30°С), так и более 3 часов (при температуре ниже 14°С).
При пасмурной погоде, а так же в тени ОЗК можно носить в полтора раза дольше.
Если вам интересно узнать о видах и функциях костюма пескоструйщика, предлагаем прочитать об этом в отдельной статье.На что следует обратить внимание при выборе одноразового комбинезона Каспер, мы расскажем здесь.
А о назначении и сферах применения костюма для защиты от повышенных температур читайте тут.
Правила хранения
Следует помнить, что малейшее нарушение целостности любой части комплекта ОЗК может повлечь за собой тяжёлые для носителя последствия.
Поэтому рекомендуется хранить костюм в специальном тканевом чехле, без лишней надобности не разворачивать.
После долгого хранения, но перед применением следует визуально оценить целостность плаща, перчаток, чулок, наличие и работоспособность шпеньков, тесёмок, закрепок.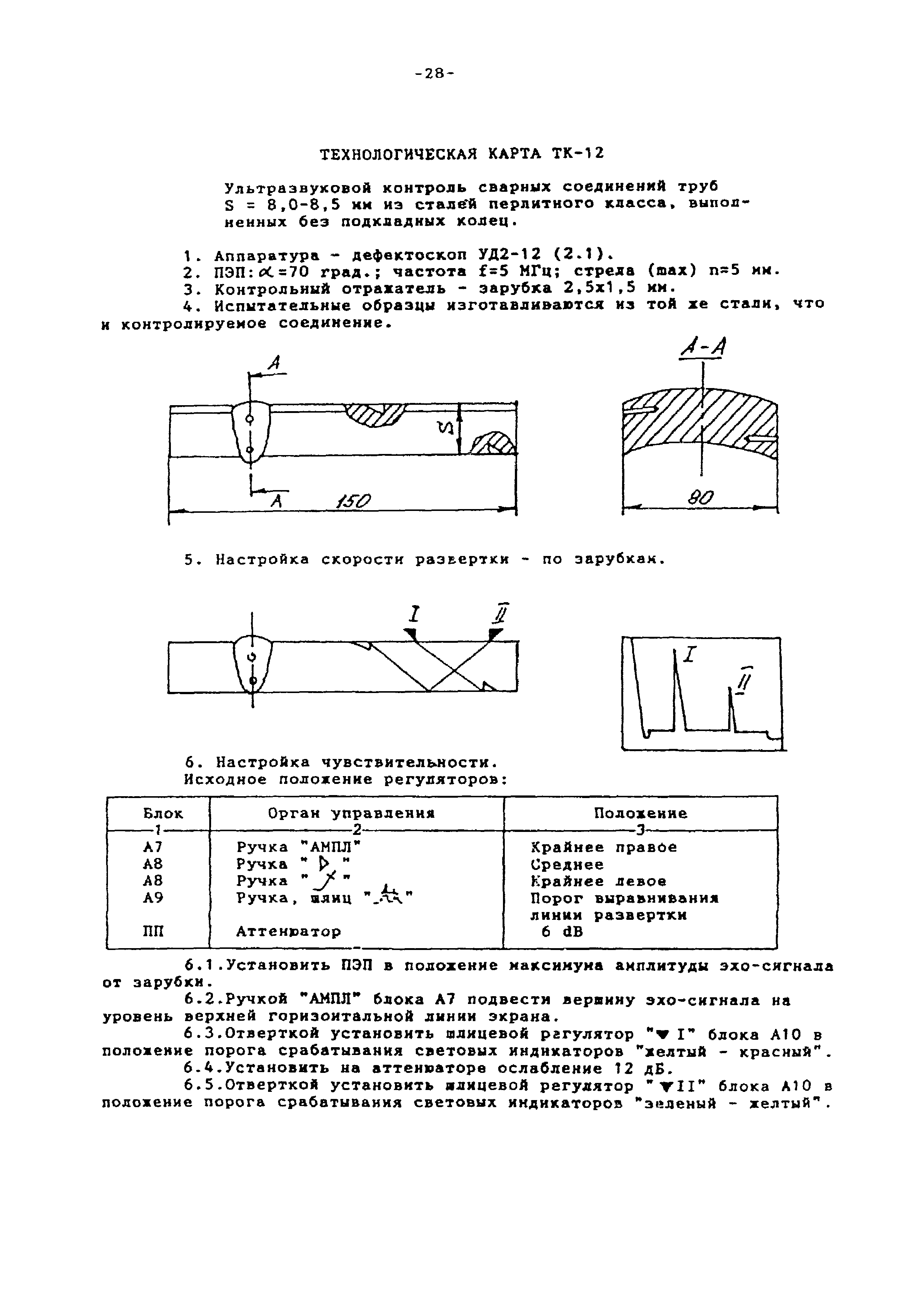
Проверить размеры костюма, заменить на более подходящий комплект при необходимости.
ОЗК можно использовать многократно, но после каждого столкновения с радиоактивным и биохимическим воздействием необходима специальная обработка.
ОЗК — надёжный и достаточно универсальный инструмент для защиты человека от ряда опасных факторов окружающей среды антропогенного происхождения.Как и любой качественный инструмент, он будет служить долго и надёжно только в том случае, если тщательно соблюдать правила эксплуатации и хранения, которые в случае с ОЗК совершенно не сложные.
8.2 DGS/AVG (АРД-диаграммы) | Olympus IMS
АРД-диаграммы
АРД-диаграммы – метод определения размеров дефектов путем сравнения амплитуды эхо-сигнала от отражателя с амплитудой эхо-сигнала от плоскодонного отверстия, расположенного на той же глубине или расстоянии. Это известно как Эквивалентный размер отражателя или ERS. Аббревиатура АРД (DGS – Distance/Gain/Size) означает «амплитуда/расстояние/диаметр», также известно как AVG (с немецкого Abstand Verstarkung Grosse). Данная техника очень долго сводилась к механическому сравнению амплитуд эхо-сигналов с отображенными кривыми. Современные цифровые дефектоскопы позволяют изображать кривые с учетом процедуры калибровки и автоматически вычислять ERS максимума в стробе. Кривые выводятся из полученной схемы рассеяния пучка данного преобразователя, на основе частоты ПЭП и диаметра элемента с использованием одной точки калибровки. Можно учитывать затухание в материале и особенности акустического контакта калибровочного и контрольного образцов. АРД – является изначально математическим методом, основанным на отношении профиля луча круглого ПЭП и измеряемых свойств материала к круглым дисковым отражателям. С тех пор, данный метод был применен к квадратным элементам и даже раздельно-совмещенным ПЭП; в последнем случае конфигурация кривых задается эмпирическим путем. Пользователь должен сам определить, насколько полученные результаты АРД сопоставимы с реальными дефектами в объекте контроля.
Данная техника очень долго сводилась к механическому сравнению амплитуд эхо-сигналов с отображенными кривыми. Современные цифровые дефектоскопы позволяют изображать кривые с учетом процедуры калибровки и автоматически вычислять ERS максимума в стробе. Кривые выводятся из полученной схемы рассеяния пучка данного преобразователя, на основе частоты ПЭП и диаметра элемента с использованием одной точки калибровки. Можно учитывать затухание в материале и особенности акустического контакта калибровочного и контрольного образцов. АРД – является изначально математическим методом, основанным на отношении профиля луча круглого ПЭП и измеряемых свойств материала к круглым дисковым отражателям. С тех пор, данный метод был применен к квадратным элементам и даже раздельно-совмещенным ПЭП; в последнем случае конфигурация кривых задается эмпирическим путем. Пользователь должен сам определить, насколько полученные результаты АРД сопоставимы с реальными дефектами в объекте контроля.
Пример типичной кривой АРД представлен ниже. Самая верхняя кривая представляет относительную амплитуду эхо-сигнала, исходящего от плоского отражателя (в дБ), на разном расстоянии от преобразователя; кривые ниже представляют относительную амплитуду эхо-сигналов, исходящих от все более маленьких дисковых отражателей, на одной шкале расстояний.
Самая верхняя кривая представляет относительную амплитуду эхо-сигнала, исходящего от плоского отражателя (в дБ), на разном расстоянии от преобразователя; кривые ниже представляют относительную амплитуду эхо-сигналов, исходящих от все более маленьких дисковых отражателей, на одной шкале расстояний.
В современных цифровых дефектоскопах, АРД-диаграммы обычно строятся на основе опорной калибровки известного элемента, например донного отражателя или плоскодонного отверстия на заданной глубине. С помощью этой точки калибровки можно построить всю кривую, с учетом характеристик ПЭП и свойств материала. Вместо изображения всей серии кривых, прибор обычно отображает одну кривую на основе размера выбранного отражателя (порог выявляемости). На приведенном ниже примере, верхняя кривая представляет график АРД для дискового отражателя 2 мм на глубине от 10 до 50 мм. Нижняя кривая – опорная кривая, построенная на 6 дБ ниже. На экране слева, красный строб обозначает отражение от плоскодонного отверстия диаметром 2 мм на глубине 20 мм. Поскольку отражатель равен выбранному уровню выявляемости, максимум сигнала соответствует кривой на данной глубине. На экране справа, в стробе, расположен другой отражатель на глубине примерно 26 мм. На основе высоты и глубины залегания отражателя по отношению к кривой, прибор вычислил ERS 1,5 мм.
Поскольку отражатель равен выбранному уровню выявляемости, максимум сигнала соответствует кривой на данной глубине. На экране справа, в стробе, расположен другой отражатель на глубине примерно 26 мм. На основе высоты и глубины залегания отражателя по отношению к кривой, прибор вычислил ERS 1,5 мм.
NSW (П411) Прямые ПЭП поперечных волн
| Внешний вид преобразователей NSW (П411) |
Направление поляризации поперечных ультразвуковых волн |
Габаритные размеры |
Прямые контактные преобразователи поперечных волн, тип NSW(П411), содержат специальные пъезоэлементы, создающие сдвиговые колебания. Эти преобразователи генерируют и принимают линейно поляризованные поперечны волны бегущие перпендикулярно поверхности ввода.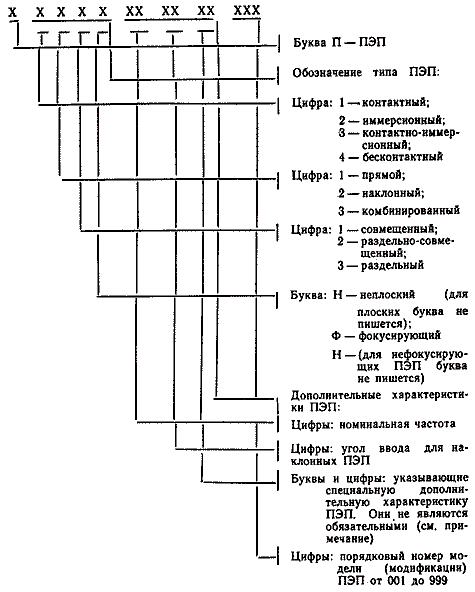
Расшифровка обозначения NSW — Normal (Incidence) Shear Wave (Transducer), затем следует частота ультразвуковых колебаний (МГц). В скобках указано российское обозначение ПЭП -П411.
Для ввода поперечных волн в изделия не подходят обычные контактные жидкости. Необходимо использовать специальную очень вязкую контактную пасту «Миасс-ПК» обладающую высоким коэффициентом передачи сдвиговых колебаний.
Обычно преобразователи NSW(П411) применяют для измерения скорости поперечных волн в материалах. В дальнейшем значении скорости поперечной волны используют для расчета модуля сдвига.
Преобразователи NSW (П411) являются импортозамещающими аналогами известных ПЭП фирмы Olympus серии V150-V157 и V220-V222.
Технические характеристики
| Наименование преобразователя |
Частота (МГц) |
Условная чувствительность по донному эхосигналу в мере СО-2, не менее (дБ) [1] |
Длительность РШХ, не более (мкс) [2] |
Длительность эхосигнала, не более (мкс) [3] |
| NSW-1,0 (П411-1,0) | 1,0 | 40 | 38 | 3,0 |
| NSW-1,25 (П411-1,25) | 1,25 | 40 | 38 | 3,0 |
| NSW-2,0 (П411-2,0) | 2,0 | 30 | 34 | 2,0 |
| NSW-2,5 (П411-2,5) | 2,5 | 20 | 28 | 1,5 |
| NSW-4,0 (П411-4,0) | 4,0 | 15 | 18 | 1,0 |
| NSW-5,0 (П411-5,0) | 5,0 | 12 | 17 | 0,8 |
Примечания:
В таблице указаны значения технических параметров измеренных с помощью дефектоскопа УД9812.
[1] Условную чувствительность находят как запас усиления дефектоскопа (дБ) при настройке по донному эхосигналу в мере СО-2 (высота 59мм).
[2] Длительность РШХ (реверберационно-шумовая характерстика) определяют на уровне условной чувствительности, см. примечание [1]
[3] Длительность эхосигнала определяют на уровне -6дБ от его максимума.
Примеры применения
| Прозвучивание меры СО-2. Преобразователь NSW-5,0 (П411-5,0) | Донный эхосигнал поперечных волн в мере СО-2. Преобразователь NSW-2,5 (П411-2,5) |
| Прозвучивание стального образца толщиной 30мм. Преобразователь NSW-2,5 (П411-2,5) | Донные эхосигналы поперечных волн в стальном образце 30мм. Преобразователь NSW-2,5 (П411-2,5) |
«Центраскан» с композитным излучателем
|
|||||||||
Ультразвуковые преобразователи к дефектоскопам УД2-70, ПЕЛЕНГ-115 и УД2-12
|
|||||||||
Стандартные образцы ультразвукового контроля CO 2, CO 3, CO 3P
|
|||||||||
Наклонные ультразвуковые преобразователи к дефектоскопам А1212 МАСТЕР ЛАЙТ, А1212 МАСТЕР ПРОФИ, А1214 ЭКСПЕРТ
|
|||||||||
Раздельно-совмещенные ультразвуковые преобразователи к дефектоскопам А1212 МАСТЕР ЛАЙТ, А1212 МАСТЕР ПРОФИ, А1214 ЭКСПЕРТ, А1209
|
|||||||||
Совмещенные ультразвуковые преобразователи к дефектоскопам А1212 МАСТЕР ЛАЙТ, А1212 МАСТЕР ПРОФИ, А1214 ЭКСПЕРТ, А1209
|
|||||||||
Низкочастотные преобразователи к дефектоскопу А1220 МОНОЛИТ
|
|||||||||
Стандартные образцы предприятия
|
|||||||||
Датчики и аксессуары для высокоточных (прецизионных) толщиномеров и дефектоскопов Olimpus
|
|||||||||
Ультразвуковые преобразователи П112
|
|||||||||
Эталонный образец (мера) СО-2
|
|||||||||
Эталонный образец (мера) СО-3
|
|||||||||
Эталонный образец (мера) СО-3Р
|
|||||||||
Стандартный образец СО-1
|
|||||||||
Эталонный образец (мера) V1
|
|||||||||
Эталонный образец (мера) V2
|
|||||||||
Плоские и трубные настроечные образцы
|
|||||||||
Стандартные образцы для ультразвуковой толщинометриии
|
|||||||||
Контрольные образцы для определения характеристик ПЭП при контроле объектов атомной энергетики
|
|||||||||
Комплект мер толщины МЭТ-300
|
|||||||||
Комплект образцов КМД4-0
|
|||||||||
Меры твердости МТБ-1
|
|||||||||
Меры твердости МТР-1
|
|||||||||
Меры твердости МТВ-1
|
|||||||||
Меры твердости МТСР-1
|
|||||||||
 Они имеют исключительное акустическое соответствие пластикам и другим материалам с низким акустическим сопротивлением. CentraScan представлены в широком диапазоне частот, размеров и типов, включая контактные, иммерсионные, наклонные, раздельно-совмещенные датчики и датчики с защитными прокладками. Во всех датчиках CentraScan предусмотрены стандартные тест-формы TP103. Аксессуары к датчикам приведены в Каталоге Ультразвуковых Датчиков фирмы Panametrics-NDT
Они имеют исключительное акустическое соответствие пластикам и другим материалам с низким акустическим сопротивлением. CentraScan представлены в широком диапазоне частот, размеров и типов, включая контактные, иммерсионные, наклонные, раздельно-совмещенные датчики и датчики с защитными прокладками. Во всех датчиках CentraScan предусмотрены стандартные тест-формы TP103. Аксессуары к датчикам приведены в Каталоге Ультразвуковых Датчиков фирмы Panametrics-NDT

 Призма выполнена из плексигласа или полиимида, что обеспечивает длительный срок службы и хорошее акустическое согласование даже при работе по грубым и корродированным поверхностям.
Призма выполнена из плексигласа или полиимида, что обеспечивает длительный срок службы и хорошее акустическое согласование даже при работе по грубым и корродированным поверхностям.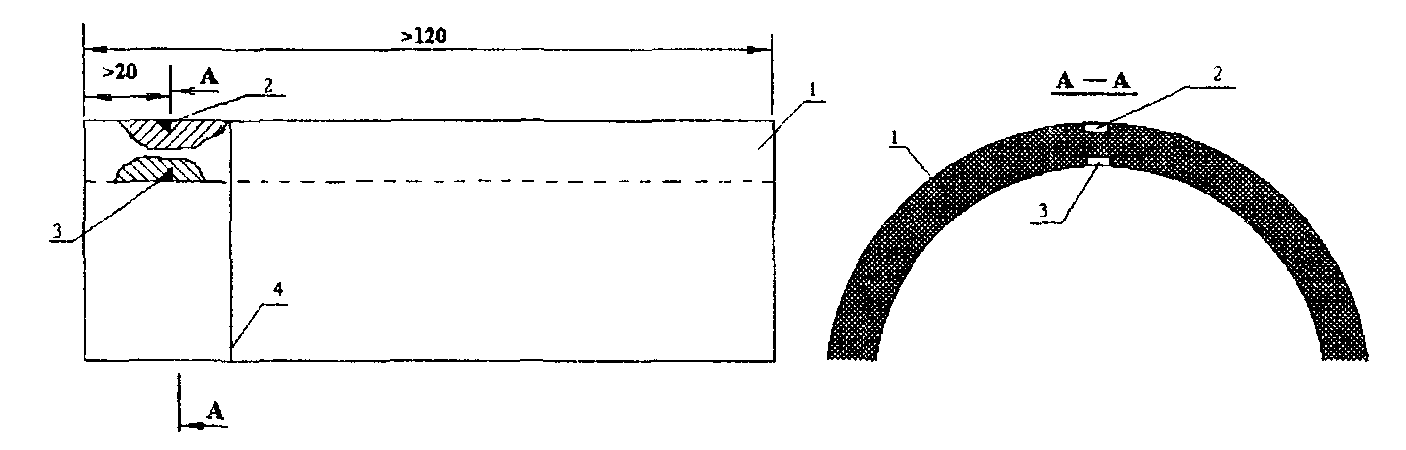 Геометрические размеры соответствуют требованиям ГОСТ Р 55724-2013. Скорость распространения продольной волны в материале образца при температуре 20±5 °С составляет 5900±59 м/с. Радиус образца равен 55мм. Образцы СО-2 и СО-3 входят в обязательный перечень оборудования необходимого для аттестации лабораторий неразрушающего контроля по ультразвуковому методу. Комплект поставки: образец (мера) СО-2, паспорт, сертификат о калибровке собственной метрологической службы.
Геометрические размеры соответствуют требованиям ГОСТ Р 55724-2013. Скорость распространения продольной волны в материале образца при температуре 20±5 °С составляет 5900±59 м/с. Радиус образца равен 55мм. Образцы СО-2 и СО-3 входят в обязательный перечень оборудования необходимого для аттестации лабораторий неразрушающего контроля по ультразвуковому методу. Комплект поставки: образец (мера) СО-2, паспорт, сертификат о калибровке собственной метрологической службы. Образец СО-3Р изготавливается из стали марки 20 в соответствии с требованиям ГОСТ 18576-96. Комплект поставки: образец СО-3Р, паспорт, сертификат о калибровке.
Образец СО-3Р изготавливается из стали марки 20 в соответствии с требованиям ГОСТ 18576-96. Комплект поставки: образец СО-3Р, паспорт, сертификат о калибровке. Время распространения ультразвуковых колебаний в прямом и обратном направлении 20±1 мкс. Образец СО-1 поставляется в комплекте с пасопртом и метрологическим свидетельством.
Время распространения ультразвуковых колебаний в прямом и обратном направлении 20±1 мкс. Образец СО-1 поставляется в комплекте с пасопртом и метрологическим свидетельством.
 СОПы изготавливаются в соответствии с требованиями нормативной документации регулирующей порядок проведения УЗК в соответствующих областях промышленности. Каждый образец имеет паспорт и сертификат калибровки сроком действия 3 года. Возможно изготовление настроечных образцов из материалов, аналогичных материалам ОК.
СОПы изготавливаются в соответствии с требованиями нормативной документации регулирующей порядок проведения УЗК в соответствующих областях промышленности. Каждый образец имеет паспорт и сертификат калибровки сроком действия 3 года. Возможно изготовление настроечных образцов из материалов, аналогичных материалам ОК.
 mega-nk.ru/#Комплект мер эквивалентной ультразвуковой толщины МЭТ-300, предназначен для настройки и первичной поверки ультразвуковых толщиномеров и измерителей координат УЗ дефектоскопов в диапазоне толщин от 0,5 до 300мм.
mega-nk.ru/#Комплект мер эквивалентной ультразвуковой толщины МЭТ-300, предназначен для настройки и первичной поверки ультразвуковых толщиномеров и измерителей координат УЗ дефектоскопов в диапазоне толщин от 0,5 до 300мм. В отличие от метода Роквелла, измерение твердости по Бринеллю производят до упругого восстановления материала. Наконечник вдавливают в поверхность образца специальным прессом, через 30 секунд после приложения нагрузки измеряют сферический отпечаток, по размерам которого судят о твердости испытуемого материала.
В отличие от метода Роквелла, измерение твердости по Бринеллю производят до упругого восстановления материала. Наконечник вдавливают в поверхность образца специальным прессом, через 30 секунд после приложения нагрузки измеряют сферический отпечаток, по размерам которого судят о твердости испытуемого материала. Ресурс мер твердости определяется правилом согласно которому расстояние между центрами двух соседних отпечатков должно быть не менее четырех диаметров отпечатка (но не менее 2 мм), расстояние от центра отпечатка до края образца должно быть не менее 2,5 диаметра отпечатка (но не менее 1 мм). Описание испытаний методом Роквелла содержится в ГОСТ 9013-059 Металлы. Метод измерения твердости по Роквеллу.
Ресурс мер твердости определяется правилом согласно которому расстояние между центрами двух соседних отпечатков должно быть не менее четырех диаметров отпечатка (но не менее 2 мм), расстояние от центра отпечатка до края образца должно быть не менее 2,5 диаметра отпечатка (но не менее 1 мм). Описание испытаний методом Роквелла содержится в ГОСТ 9013-059 Металлы. Метод измерения твердости по Роквеллу. Твердость по Виккерсу рассчитывается как отношение нагрузки Р к площади поверхности полученного отпечатка. Метод Виккерса позволяет определять твёрдость азотированных и цементированных поверхностей, а также тонких листовых материалов.
Твердость по Виккерсу рассчитывается как отношение нагрузки Р к площади поверхности полученного отпечатка. Метод Виккерса позволяет определять твёрдость азотированных и цементированных поверхностей, а также тонких листовых материалов. Ресурс мер твердости Супер-Роквелла ограничен расстоянием между центрами двух соседних отпечатков которое должно составлять не менее трёх диаметров отпечатка. Расстояние от центра отпечатка до края образца должно составлять не менее 2,5 диаметров отпечатка. Методу супер Роквелла полностью посвящен ГОСТ 22975-78.
Ресурс мер твердости Супер-Роквелла ограничен расстоянием между центрами двух соседних отпечатков которое должно составлять не менее трёх диаметров отпечатка. Расстояние от центра отпечатка до края образца должно составлять не менее 2,5 диаметров отпечатка. Методу супер Роквелла полностью посвящен ГОСТ 22975-78.УЗК-Э-СП-11 на тележке | Ланфор
УЗК — устройство заготовки кабельных каналов, предназначено для облегчения процесса протягивания (прокладки) кабеля, провода в кабельной канализации, межэтажных конструкциях, трубах, кабельных стояках, кабель каналах и т.д.
УЗК-Э-СП – это УЗК с силовым элементом из полностью диэлектрического стеклопластикого прутка покрытого полиэтиленовой защитной оболочкой (далее стеклопруток), на концах которого закреплены стальные оцинкованные наконечники с навинчивающимися насадками для заготовки канала и крепления кабеля (провода, веревки и т. д.) к прутку при протягивании.
д.) к прутку при протягивании.
Полиэтиленовое покрытие УЗК защищает стеклопруток от расслоения (разрушения) и снижает трение, значительно облегчая тем самым протяжку УЗК в кабельной канализации, межэтажных конструкциях, трубах, кабельных стояках, кабель каналах и т.д.
Транспортировочная тележка с разматывающим устройством ТТ-500 — представляет собой каркас, на оси которого крепиться кассета с прутком в защитном полимерном покрытии. На каркасе тележки также закреплены направляющие, через которые пропускают стеклопруток при работе с УЗК. ТТ-500 имеет два металлических колеса с прорезиненным покрытием для перемещения на рабочем месте. Емкость кассеты ТТ-500 — 500 метров стеклопрутка D=11 mm.
Особенности ТТ-500:
- Прочные металлические колеса с прорезиненными катками.
- Простая система замены кассеты.
- Оптимальный баланс надежности конструкции, размеров и веса.
- Удобная транспортабельность тележки.
Расшифровка маркировки УЗК-Э-СП-11/X:
УЗК — устройство заготовки кабельных каналов (протяжка, кабельный кондуктор, буш).

Э — устройство серии «ЭКОНОМ» (стеклопруток производства России)
СП — силовой элемент — стеклопластиковый пруток
11 — диаметр силового элемента в полимерной оболочке 11мм, допустимые отклонения от -0.2мм до +0.5мм
X — длина силового элемента от 50 до 500 метров, допустимые отклонения от -0.1м до +0.5м.
Наш менеджер свяжется с вами в ближайшее время
Декодирование алгебраических списков с оптимальной скоростью с использованием узких полей классов лучей
Abstract
Мы используем теорию полей классов, в частности модули Дринфельда ранга 1, для построения семейства асимптотически хороших алгебро-геометрических (AG) кодов над фиксированными алфавитами. В поле размера 2 эти коды находятся в пределах 2 / (ℓ − 1) от границы Синглтона. Поля функций, лежащие в основе этих кодов, являются подполями с циклической группой Галуа поля классов узких лучей определенных функциональных полей. Полученные коды «сворачиваются» с помощью генератора группы Галуа.Это обобщает более раннюю работу первого автора по свернутым кодам AG, основанным на полях циклотомических функций. Используя теорему Чеботарева о плотности, мы доказываем наличие большого количества инертных мест большой степени в нашем циклическом расширении и используем это для разработки линейно-алгебраического алгоритма для перечисления этих свернутых кодов с точностью до доли ошибок, приближающейся к 1-R, где R это ставка. Декодирование списка может выполняться за полиномиальное время с учетом полиномиального количества предварительно обработанной информации о поле функции.
Поля функций, лежащие в основе этих кодов, являются подполями с циклической группой Галуа поля классов узких лучей определенных функциональных полей. Полученные коды «сворачиваются» с помощью генератора группы Галуа.Это обобщает более раннюю работу первого автора по свернутым кодам AG, основанным на полях циклотомических функций. Используя теорему Чеботарева о плотности, мы доказываем наличие большого количества инертных мест большой степени в нашем циклическом расширении и используем это для разработки линейно-алгебраического алгоритма для перечисления этих свернутых кодов с точностью до доли ошибок, приближающейся к 1-R, где R это ставка. Декодирование списка может выполняться за полиномиальное время с учетом полиномиального количества предварительно обработанной информации о поле функции.
Наша конструкция дает алгебраические коды над алфавитами постоянного размера, которые могут быть декодированы по списку с точностью до границы Синглтона — в частности, для любой желаемой скорости R∈ (0,1) и константы ε> 0 мы получаем коды с размером алфавита ( 1 / ε) O (1 / ε2), которые могут быть декодированы по списку с точностью до доли ошибок 1-R-ε, ограничивая соседние сообщения подпространством с NO (1 / ε2) элементами. Предыдущие результаты декодирования списков с точностью до доли ошибок 1-R-ε по алфавитам постоянного размера были либо основаны на конкатенации, либо предполагали взятие тщательно отобранного подкода алгебро-геометрических кодов.Напротив, наш результат показывает, что эти свернутые алгебро-геометрические коды сами обладают заявленным свойством декодирования списков.
Предыдущие результаты декодирования списков с точностью до доли ошибок 1-R-ε по алфавитам постоянного размера были либо основаны на конкатенации, либо предполагали взятие тщательно отобранного подкода алгебро-геометрических кодов.Напротив, наш результат показывает, что эти свернутые алгебро-геометрические коды сами обладают заявленным свойством декодирования списков.
Ключевые слова
Свернутые коды
Автоморфизм
Поля классов
Теорема Чеботарева о плотности
Кодирование и декодирование
Рекомендуемые статьиЦитирующие статьи (0)
Просмотр аннотацииCopyright © 2014 Elsevier Inc. Все права защищены.
Рекомендуемые статьи
Цитирующие статьи
Метод декодирования на основе распознавания образов для отрицательного импульсного сигнала нисходящей линии связи с узкой шириной импульса
На рисунке 3 показана блок-схема принципа распознавания образов в этой статье.Ядро модели распознавания образов использует матрицу евклидовых расстояний метода ближайшего соседа в качестве дискриминантной функции для идентификации всех сегментов сигнала с аналогичными характеристиками формы сигнала.
Рис.3 Схемы художественного рисунка Принцип
распознаванияшаблона математическая модель
(1) Определить сегмент опорного сигнала. Опорный сегмент выбирается на первом сегменте спадающего фронта формы сигнала (также может быть выбран сегмент нарастающего фронта, в этой статье спадающий фронт используется в качестве объекта анализа), а в методе выбора может использоваться алгоритм начальной кластеризации k-средних Метод выбора центра, как правило, бывает «выбор на основе опыта», «случайный метод» и «метод плотности» (Xing and Xiao 2010).
Эта статья выбирает «метод плотности», чтобы определить сегмент опорного сигнала.
Если минимальная ширина импульса сигнала занимает 8 с \ (T _ {\ min} \), а частота дискретизации \ (F _ {{\ text {s}}} \) составляет 100 Гц, минимальное количество данных дискретизации точек \ (N \) для одной выборки равно 800. Чтобы полностью выразить характеристики формы сигнала спадающего фронта сигнала, время выборки \ (T_ {s} \) исследовательского сегмента должно быть выбрано так, чтобы составлять 10% -40% всего сегмента на заднем крае. {T}} $$
{T}} $$
(5)
В этой статье анализируются данные об амплитуде сигнала, чтобы найти сегменты заднего фронта сигнала с аналогичными характеристиками.\ (B_ {0} \) представляет собой отправную точку. Чтобы гарантировать точность модели, шаг алгоритма установлен на 1, а матрица разности \ (L_ {1} \) между амплитудами сигналов записывается как:
$$ L_ {1} = B_ {0} — b_ {i} $$
(6)
Среди них \ (b_ {i} \) — это сегмент сигнала, который непрерывно собирается во времени \ (T_ {s} \), а его последовательность данных — \ (b_ {i} = \ {x (T_ {0} + i), x (T_ {0} + 1 + i), \ ldots, x (T_ {0} + T_ {s} + i) \} \), \ (i = 1,2, \ ldots, n \) и \ (n \) — количество пройденных данных.{{T_ {0} + i}} {L _ {{1_ {j}}}}}} {{T_ {0}}} $$
(7)
Принимая матрицу разностей \ (L_ {1} \) (\ (L_ {1} = \ left \ {{\ begin {array} {* {20} c} {L_ {11}} & {L_ {12) }} & \ ldots & {L_ {1n}} \\ \ end {array}} \ right \} \)) двух сегментов сигнала, а средняя матрица разности (\ (L_ {2} \) является значение, которое может быть описано как матрица 1 × 1) в качестве матрицы выборки и эталонной матрицы в вышеупомянутой модели матрицы евклидовых расстояний. {T}} $$
{T}} $$
(8)
Последовательность матрицы \ (D \) выражается как \ (D = \ left \ {{\ begin {array} {* {20} c} {D_ {1}} & {D_ {2}} & \ ldots & {D_ {n}} \\ \ end {array}} \ right \} \), \ (D \) — это матрица размером 1 × \ (n \), которая представляет собой количество данных, которые могут быть пройдены .
Алгоритм декодирования
Используя элементы в матрице евклидовых расстояний \ (D \) в качестве функциональной кривой и кривой анализа, можно определить ее минимальные значения \ (T \), которые представляют собой начальную точку каждого подобного сегмента \ (T = \ {T_ {0}, T_ {1}, T_ {2}, \ ldots, Т_ {j} \} \), где элемент \ (Т_ {0} \) представляет собой начальную точку отрезка опорного сигнала .
Вычисление данных сегмента сигнала, представленных им как \ (B_ {1} \), \ (B_ {2} \), \ (\ ldots \), \ (B_ {j} \), и последовательность \ ( B_ {j} \) можно записать как:
$$ B_ {j} = [x (T_ {j} + 1), \; x (T_ {j} + 1 + 1), \ ldots, x ( T_ {j} + 1 + T_ {s})] $$
(9)
Среди них \ (j = 1, \; 2, \; \ ldots \ ;, k — 1 \), где \ (k \) представляет количество спадающих фронтов всей формы сигнала.
Для повышения точности определения начальной точки команды нисходящей линии связи в этой статье используется конкретная структура заголовка синхронизации для определения начальной точки кодированного сигнала нисходящей линии связи.Структура заголовка синхронизации должна существенно отличаться от передаваемых символов. Например, структура «8 с-8 с-20 с-8 с» может использоваться для длительности импульса 8 с. Заголовок синхронизации содержит два аналогичных сегмента, поэтому при декодировании сигнала нисходящей линии связи можно начать отсчет от аналогичного сегмента \ (B_ {2} \).
- (1)
Рассчитайте фактическую минимальную длительность импульса \ (T_ {A — \ min} \). В случае добавления сегмента сигнала заголовка синхронизации можно вычислить фактическую минимальную ширину импульса при искажении формы сигнала:
$$ T_ {A — \ min} = \ frac {{T_ {1} — T_ {0 }}} {2} $$
(10)
- (2)
Расшифровать соответствующее командное слово.
Фактическая минимальная ширина импульса может использоваться для определения кода инструкции между каждой шириной импульса. Во-первых, нахождение длительности интервала ширины импульса \ (\ Delta T \) каждого подобного сегмента:$$ \ Delta T = \ left \ {{T_ {1} — T_ {0}, \; T_ {2} — T_ {1}, \ ldots, T_ {j} — T_ {j — 1}} \ right \} $$
(11)
 Фактическая минимальная ширина импульса может использоваться для определения кода инструкции между каждой шириной импульса. Во-первых, нахождение длительности интервала ширины импульса \ (\ Delta T \) каждого подобного сегмента:
Фактическая минимальная ширина импульса может использоваться для определения кода инструкции между каждой шириной импульса. Во-первых, нахождение длительности интервала ширины импульса \ (\ Delta T \) каждого подобного сегмента:Расчет целочисленного значения \ (q_ {j} \) фактической минимальной ширины импульса \ (T_ {A — \ min} \):
$$ q_ {j} = \ left [{\ frac {\ vartriangle T} {{T_ {A — \ min}}}} \ right] = \ left [{\ frac {{T_ {j} — T_ {j — 1}}} {{T_ {A — \ min}}}} } \ right] $$
(12)
Среди них \ (j = 1,2, \ ldots, k — 1 \).Удалите сегмент сигнала, занятый заголовком синхронизации, затем начните с промежуточной точки данных \ (x [\ frac {{(2T_ {v} + T_ {s} + 1)}} {2}] \) аналогичного сегмента \ (B_ {v} \) (\ (v = 2,3, \ ldots, k — 1 \)) и запишите его как новую последовательность данных \ (C_ {l} \) с длиной шага \ (T_ { A — \ min} \) последовательность данных \ (C_ {l} \) выглядит следующим образом:
$$ C_ {l} = x \ left [{\ frac {{(2T_ {i} + T_ {0 } + 1)}} {2} + l} \ right] $$
(13)
Среди них \ (l = 1,2, \ ldots, T_ {A — \ min} \), вычисляющее среднее значение последовательности как \ (c_ {w} \):
$$ c_ {w } = \ frac {{\ sum \ limits_ {l = 1} ^ {{T_ {A — \ min}}} {C_ {l}}}} {{T_ {A — \ min}}} $$
(14)
Среди них \ (w \) — количество командных слов (кодовых единиц). Присвойте значение элементу кода \ (M \) из \ (\ Delta T \), сравнив значение:
Присвойте значение элементу кода \ (M \) из \ (\ Delta T \), сравнив значение:
$$ M_ {w} = \ left \ {{\ begin {array} {* {20} c} {0, \; c_ {w} \ ge x [\ frac {{(2T_ {v} + T_ {s} + 1)}} {2}]} \\ {1, \; c_ {w} (15) Между тем необходимо удалить данные \ (x (\ Delta T — q_ {j} \ cdot T_ {A — \ min}) \). Конкретный процесс алгоритма декодирования командного слова показан на рис.4: для командного слова Размещение клеток в гиппокампе млекопитающих сигнализирует само-локализацию с разреженными пространственно стабильными полями возбуждения. На основании наблюдения за активностью клеток места можно точно расшифровать местонахождение животного. Возможность точной самоопределения критически важна для большинства подвижных организмов.У млекопитающих клетки места в гиппокампе, по-видимому, являются центральным компонентом сети мозга, ответственной за эту способность. В этой работе мы записали активность популяции нейронов гиппокампа от свободно перемещающихся грызунов и провели нейронное декодирование для определения местоположения животных. Мы обнаружили, что подход машинного обучения с использованием рекуррентных нейронных сетей (RNN) позволяет нам предсказать истинное положение грызунов более точно, чем стандартный байесовский метод с плоскими априорными значениями (т.е.е. оценка максимального правдоподобия, MLE), а также байесовский подход с памятью (то есть с априорными данными, полученными на основе прошлой активности). RNN могут учитывать прошлую нейронную активность, не делая предположений о статистике срабатывания нейронов. Кроме того, проанализировав репрезентации, полученные в сети, мы смогли определить, какие нейроны и какие аспекты их активности больше всего способствовали точному декодированию. Образец цитирования: Tampuu A, Matiisen T, lafsdóttir HF, Barry C, Vicente R (2019) Эффективное нейронное декодирование собственного местоположения с глубокой повторяющейся сетью.PLoS Comput Biol 15 (2):
e1006822.
https://doi.org/10.1371/journal.pcbi.1006822 Редактор: Франческо П. Батталья,
Radboud Universiteit Nijmegen, НИДЕРЛАНДЫ Поступила: 04.01.2018; Одобрена: 28 января 2019 г .; Опубликовано: 15 февраля 2019 г. Авторские права: © 2019 Tampuu et al. Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника. Доступность данных: Все файлы данных доступны в общедоступных репозиториях. Финансирование: AT, TM и RV были поддержаны Эстонским научным советом, номер проекта PUT 1476 (https: // www.etis.ee/Portal/Projects/Display/52ed4301-f2ef-4364-9770-397e31936f93?lang=ENG) и проект Эстонского центра передового опыта в области информационных технологий (EXCITE) номер TK148 (https://www.etis.ee/Portal / Projects / Display / fd0aeffa-a7d3-4191-b468-0f44aa2847af? Lang = ENG). CB финансировался Королевским обществом (https://royalsociety.org) и Wellcome Trust (https://wellcome.ac.uk). Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи. Конкурирующие интересы: Авторы заявили, что никаких конкурирующих интересов не существует. Клетки места, пирамидные нейроны, обнаруженные в СА1 и СА3 гиппокампа млекопитающих [1–4], демонстрируют пространственно ограниченные рецептивные поля, называемые полями мест. В целом активность клеток места считается стабильной [5, 6]; Поля места обычно устойчивы к устранению специфических сигналов окружающей среды [7, 8], сохраняются между посещениями места [9] и в открытом поле не сильно зависят от поведения животного [2, 5]. При воздействии нового помещения корреляты срабатывания клеток места быстро «переназначаются»; Поля места меняют свою скорость стрельбы и относительное положение, формируя отчетливое представление нового пространства [10–12].По этим причинам широко распространено мнение, что клетки места обеспечивают нейронную основу самоопределения, сигнализируя о положении животного относительно окружающей его среды и, таким образом, являясь необходимым элементом для контроля пространственного поведения, такого как навигация, и сохранения пространственного положения. Однако, хотя активность клеток места сильно модулируется самоопределением, эта взаимосвязь нетривиальна и не исключительна.Например, во время отдыха и коротких пауз, а также во время движения, код места может отделяться от текущего местоположения животного и воспроизводить траектории через вольер [15]; «Воспроизведение» предыдущего опыта [16] или, возможно, предвидение будущих действий [17]. Аналогичным образом, когда животные бегают по линейным взлетно-посадочным полосам или выполняют ограниченные навигационные задачи, такие как чередование Т-образного лабиринта, активность клеток места сильно модулируется поведением, устраняя неоднозначность направления движения [18], предполагаемых и ретроспективных траекторий [19, 20] и степень вовлеченности в задачу [21].Кроме того, хотя поля мест повторяются, они не статичны. Обычный подход, используемый для исследования нейронных репрезентаций, таких как репрезентации ячеек места, — это декодирование; Точность, с которой переменная, такая как мое местоположение, может быть декодирована мозгом, устанавливает полезный нижний предел количества имеющейся информации [13, 14]. Чтобы лучше понять эти ограничения, мы обучили глубокую рекуррентную нейронную сеть (RNN) [31–33] декодировать местоположение грызунов по частоте активации нейронов CA1.На каждом временном шаге сети был представлен вектор, соответствующий количеству спайков клеток гиппокампа в течение заданного временного окна. После накопления информации для 100 временных шагов сети требовалось предсказать местонахождение животного — наблюдение осуществлялось в форме истинного местонахождения животного. Мы обнаружили, что декодирование с помощью обученной RNN было последовательно более точным, чем стандартный байесовский подход [14, 29] с плоскими априорными значениями (по сути, MLE), а также байесовский декодер с априорными значениями, основанными на исторической активности животных [14, 16]. .Это демонстрирует, что RNN могут фиксировать взаимосвязь между временной последовательностью нейронной активности и закодированной переменной без необходимости явных предположений о базовой модели шума или сложных вручную закодированных априорных значениях. В следующем разделе результатов мы суммируем производительность декодирования с помощью трех декодеров. Простой байесовский декодер использует счетчики всплесков из одного временного окна, сосредоточенного вокруг измерения местоположения. Он сочетает в себе вероятность появления этих всплесков в разных местах с фиксированной до принятия решения, что означает, что по сути это оценка максимального правдоподобия (MLE) . Третий декодер, рекуррентная нейронная сеть (RNN), представляет собой алгоритм машинного обучения, который учится на примерах посредством градиентного спуска [31]. В частности, предоставляя сети последовательность векторов подсчета всплесков из 100 последовательных временных окон и местоположения в центре последнего окна, алгоритм учится предсказывать последнее из первого. Поскольку сеть имеет доступ к нейронной активности из многих предыдущих временных окон, она учится использовать это как контекстную информацию для повышения точности декодирования.Обучение достигается путем постепенного изменения силы соединения в сети, чтобы минимизировать среднеквадратичную потерю ошибок. В этой работе мы использовали тип рекуррентной нейронной сети, называемой долговременной памятью (LSTM, [34]). Все представленные результаты получены с сетью, состоящей из двух слоев LSTM по 512 единиц, за которыми следует линейный выходной слой (2 значения, по одному для каждой координаты).Более подробное описание сети, ее входов и параметров обучения см. В разделе «Методы» и в коде на GitHub. Чтобы проверить способность RNN декодировать местоположение грызунов на основе активности гиппокампа, мы сначала охарактеризовали ошибку декодирования для одного животного, добывающего пищу на двумерной арене (1 м x 1 м). Записи единичных единиц были сделаны с использованием тетродов из области CA1 пяти крыс. У всех животных менее 10% зарегистрированных нейронов были интернейронами, характеризующимися узкой формой волны и высокой частотой возбуждения. Нейронные данные были обработаны для извлечения потенциалов действия, и они были назначены отдельным нейронам с использованием разницы амплитуд между каналами тетрода [35] (см. Методы). Затем входные функции для RNN-декодера состояли из количества импульсов для каждого нейрона в пределах набора временных окон.Длительность временных окон параметрически варьировалась от 200 мс до 4000 мс с шагом 200 мс. Каждое последующее окно запускалось на 200 мс позже предыдущего (это означает перекрытие 0% для окон 200 мс, перекрытие 50% для окон 400 мс, перекрытие 80% для окон 1000 мс и т. Д. См. «Извлечение признаков» в разделе «Методы»). Сеть была представлена подсчетом спайков из 100 окон, прежде чем ее попросили предсказать местоположение животного в центре последнего окна. Поскольку процесс обучения RNN является стохастическим, процедура 10-кратной перекрестной проверки (CV) выполнялась несколько раз для каждого размера окна.Для каждого из этих прогонов мы обучили 10 моделей (для каждой кратности CV) и извлекли средние и медианные результаты по складкам. Черные точки на рис. 1 соответствуют этим различным реализациям процедуры 10-кратного CV (обратите внимание на несколько точек на размер окна). К байесовским декодерам также применялась 10-кратная перекрестная проверка. Рис. 1. Точная расшифровка позиции с помощью RNN. Ошибки декодирования местоположения на основе нейронных данных CA1, записанных из среды открытого поля площадью 1 м, как функция размера временного окна.(а) показывает среднюю ошибку и (б) среднюю ошибку. Синие линии представляют ошибки декодера RNN, а красные линии — байесовских подходов. Результаты для подхода RNN усредняются по различным независимым реализациям алгоритма обучения. Черные точки отображают среднюю / медианную ошибку каждой отдельной модели. https://doi.org/10.1371/journal.pcbi.1006822.g001 Как для среднего (рис. 1a), так и для медианы (рис. 1b) ошибок валидации кривая ошибок была выпуклой с наименьшими ошибками, полученными при промежуточных значениях. .Наилучшая медианная точность декодирования была достигнута при временном окне 1200 мс (средняя ошибка = 10,18 ± 0,23 см). Лучшее среднее декодирование было достигнуто для временного окна 1400 мс (средняя ошибка = 12,50 ± 0,39) см). Использование более длинных или более коротких временных окон приводит к большему количеству ошибок — вероятно, потому, что счетчики всплесков из более коротких окон становятся все более шумными, в то время как активность CA1 животного менее специфична для определенного места для более длинных окон. Для всех временных окон точность RNN значительно превышала точность как простого байесовского декодера (пунктирная красная линия), так и байесовского декодера с памятью (сплошная красная линия). RNN имеет возможность гибко использовать информацию из всех 100 входных векторов и, таким образом, интегрировать контекстную информацию с течением времени. Это приводит к более низким средним и медианным ошибкам по сравнению с двумя базовыми байесовскими подходами. Наивный байесовский метод с плоскими априорными значениями не имеет доступа к информации о прошлой активности, что приводит к самой низкой точности. Таблица 1. Наборы данных для задач декодирования 2D и 1D. Количество точек данных, количество записанных нейронов и оптимальное временное окно для трех декодеров для каждого из 5 проанализированных животных и для обеих задач декодирования. https://doi.org/10.1371/journal.pcbi.1006822.t001 Помимо глобальных дескрипторов средней и медианной ошибки, мы также проверили распределение размеров ошибок декодирования (рис. Рис. 2. Сравнение RNN и байесовских декодеров. (a) Гистограмма размеров ошибок, сгенерированная в каждом случае с лучшим временным окном (1400 мс для RNN, 2800 мс для плоского байесовского и 2000 мс для байесовского с памятью). Оба типа байесовских декодеров допускают более очень большие ошибки (0.02% против 2,7% ошибок> 50 см). Ошибки сгруппированы в ячейки по 2 см, последняя ячейка показывает все ошибки выше 50 см. (b-c) Анализ понижающей дискретизации показывает, что декодер RNN более устойчив к небольшим размерам наборов данных. Данные от R2192 были подвергнуты субдискретизации, и все три декодера были обучены случайным подмножеством доступных нейронов. Для каждого размера выборки были отобраны 10 случайных наборов нейронов и обучены независимые модели, как и прежде, с использованием 10-кратной перекрестной проверки. Точки представляют (b) среднее значение и (c) медианную ошибку для каждого субдискретизированного набора данных.Линии указывают (б) среднее значение и (в) среднее значение медиан по наборам одинакового размера. https://doi.org/10.1371/journal.pcbi.1006822.g002 Распределение ошибок RNN имело одномодальную кривую, при этом большинство прогнозов отклонялось от истинного положения крысы на 6-8 см, а некоторые ошибки превышали 35 см ( 1,7% ошибок> 35 см, см. Рис. 2а). Байесовские классификаторы достигают не только очень низких (<2 см) ошибок, но также и множества очень больших (> 50 см) ошибок (≈8% ошибок> 35 см, ≈2.7%> 50 см; для обоих байесовских классификаторов). Во многих случаях записи единичных единиц дают меньше, чем 63 нейрона, идентифицированных из R2192. Мы предположили, что способность RNN использовать контекстную информацию будет иметь все большее значение в сценариях, где нейронные данные были более скудными. Чтобы проверить это предсказание, мы случайным образом уменьшили размер набора данных, доступного в R2192, повторив процедуру обучения и декодирования для популяций нейронов, размер которых варьируется от 5 до 55 с шагом 5.Как и ожидалось, мы увидели, что точность декодирования снижается по мере уменьшения размера набора данных. Всего мы проанализировали записи от пяти животных, когда они кормились в двухмерной среде открытого поля (1м x 1м квадрат). Для каждого из этих 5 наборов данных мы определили наилучший размер временного окна (аналогично рис. 1) для архитектуры RNN (состоящей из 2-х уровней по 512 единиц LSTM), простого байесовского декодера (MLE) и байесовского декодера с памятью.Оптимальные размеры временного окна для пяти двумерных наборов данных о кормлении приведены в верхней половине таблицы 1 вместе с длиной записи и количеством идентифицированных нейронов. В задаче двухмерного декодирования для разных животных средняя ошибка (среднее значение по перекрестной проверке) находилась в диапазоне 12,5–16,3 см, а медиана — в пределах 10,3–13,1 см (рис. Рис. 3. Пространственное декодирование животных в 2D и 1D средах. (a-b) Результат декодирования для окружения площадью 1 м². RNN неизменно превосходит два байесовских подхода во всех 5 наборах данных. Среднее и медианное значение ошибок при перекрестной проверке соответственно. (c-d) Ошибки декодирования Z-образной дорожки длиной 600 см. RNN последовательно дает более низкие ошибки декодирования, чем байесовские подходы, разница более заметна, когда учитываются средние (c), а не медианные (d) ошибки. https://doi.org/10.1371/journal.pcbi.1006822.g003 Мы также выполнили декодирование записанных одномерных наборов данных, в то время как те же 5 животных курсировали назад и вперед по Z-образной дорожке длиной 600 см для награждения, размещенной в углы и концы (таблица 1) [36]. Затем, чтобы понять, как поведенческая и нейронная изменчивость влияет на точность декодирования, мы сосредоточили внимание на результатах, полученных на крысе R2192 в квадрате 1 м — животном с наибольшим количеством нейронов и наименьшей ошибкой декодирования. Сначала мы исследовали ошибку декодирования как функцию местоположения крысы. Важно отметить, что поведение животных неоднородно — крысы посещают одни части арены чаще, чем другие (см. Рис. 4а). Поскольку для часто посещаемых регионов доступно больше обучающих данных, ожидается, что любой подход к декодированию будет наиболее точным в этих местах. Пространственное распределение ошибки декодирования для R2192, кажется, подтверждает эту гипотезу — ячейки с хорошей дискретизацией в центре корпуса и части его границ декодируются более точно (рис. 4b).Чтобы подтвердить это, мы вычислили корреляцию между ошибкой декодирования и количеством точек обучающих данных, расположенных в радиусе 10 см от прогнозируемой точки данных, обнаружив значительную отрицательную корреляцию (порядок рангов Спирмена, r = -0,16, p val ≪ 0,001, dof = 4412). Рис. 4. Анализ ошибок функции местоположения и нейронной активности для крысы R2192. (а) Траектория движения крысы в течение всего испытания.Не все части арены посещаются одинаково часто. б) средний размер ошибок, сделанных в различных областях пространства. Цвет каждого шестиугольника отображает среднюю евклидову ошибку точек данных, попадающих в шестиугольник. Более часто посещаемые области (как видно из (а)), как правило, имеют более низкую среднюю ошибку. (c) Суммарная нейронная активность в различных областях пространства. Для каждой точки данных мы суммируем количество спайков всех 63 нейронов за период 1400 мс с центром в момент регистрации местоположения. Цвет шестиугольника соответствует среднему значению по всем точкам данных, попадающим в шестиугольник.Области, где суммарная нейронная активность высока, имеют меньшую ошибку прогноза. (d) Ошибка предсказания координаты уменьшается, если животное находится ближе к стене, перпендикулярной этой координате. https://doi. Еще одним важным фактором, влияющим на точность декодирования, является распределение нейронной активности по 2D-корпусу. В частности, локальные поля записанных клеток гиппокампа не покрывают оболочку равномерно.Очевидно, что алгоритму будет сложно различать места, где нет активных ячеек. Таким образом, вполне вероятно, что области, в которых активировано больше нейронов, декодируются с более высокой точностью. Наши результаты подтверждают, что сумма числа спайков по нейронам в данном месте сильно антикоррелирована с ошибкой прогноза, сделанной в этом месте (рис. 4c, порядок рангов Спирмена, r = -0,31, p val ≪ 0,001, dof = 4412). Мы также отдельно проверили компоненты ошибки декодирования x и y . Предыдущая работа предполагает, что в случае ячеек сетки контакт с границей окружающей среды приводит к уменьшению ошибки в представлении собственного местоположения перпендикулярно этой стене [37]. Кроме того, дополнительным фактором, влияющим на точность прогнозов, была скорость движения животного. Прогнозы были более надежными, когда крыса двигалась, а не стояла. Точность любого нейронного декодера представляет собой полезную нижнюю границу информации о декодированном состоянии, содержащейся в записанных нейронах. Простой способ оценить релевантность определенных входных данных в прогнозной модели — удалить их (для выбить ) и наблюдать, как изменяется точность прогнозирования. Если входные данные удаляются перед обучением, модель может научиться компенсировать недостающую информацию — выбивание с переобучением.Однако, если входные данные удаляются после обучения — выбивание без переобучения — модель не может адаптироваться или компенсироваться. Здесь мы использовали нокаут без переучивания. RNN применялась, как и раньше, для прогнозирования местоположений на основе набора данных проверки, в котором активность одного нейрона была установлена на ноль. Процедуру выбивания повторяли для каждого входного нейрона отдельно и рассчитывали среднюю ошибку прогноза. Таким образом, мы смогли ранжировать нейроны по чувствительности — чем больше увеличивалась ошибка из-за выбивания, тем более важным был нейрон для модели. Самый влиятельный нейрон (нейрон №55) был визуально идентифицирован как тормозной нейрон на основании отсутствия четких полей возбуждения и высокой частоты возбуждения (рис. 5). В некотором роде удивительно, что этот нейрон был идентифицирован как имеющий наибольшее влияние на модель — предыдущие исследования предполагают, что тормозные клетки не предоставляют много информации о собственном местонахождении. Однако чувствительность модели к этому нейрону, вероятно, связана с его высокой частотой возбуждения. Рис. 5. Результаты нокаут-анализа. Карты скорости активации наиболее (a-e) и наименее (f) влиятельных нейронов согласно нокаут-анализу. Цветная полоса справа от каждого графика указывает скорость стрельбы в Гц. С полным набором данных средняя ошибка составила 12.50 ± 0,28 см. При выбивании нейронов 55, 26, 41, 17, 23 (пять наиболее влиятельных) и 9 (наименее влиятельных) средняя ошибка увеличилась до 14,72 см, 13,80 см, 13,66 см, 13,50 см, 13,49 см и 12,58 см соответственно. . https://doi.org/10.1371/journal.pcbi.1006822.g005 Для более чем половины нейронов, выбив их из строя, точность прогноза незначительно снизилась (меньше стандартного отклонения точности, рассчитанного по 10 реализациям полная модель). Другой способ исследовать, какие нейроны наиболее сильно влияют на точность декодирования, — это градиентный анализ. В этом анализе мы вычисляем производные функции потерь (среднеквадратическая ошибка предсказания) RNN по входам (количество спайков нейронов) в различные моменты времени. По определению эти производные показывают, насколько небольшое изменение количества выбросов влияет на ошибку. Для каждого прогнозируемого местоположения мы спросили, насколько чувствительна модель к каждому входному количеству выбросов. Поскольку наши входные данные RNN представляют собой набор из 100 векторов подсчета спайков (длина временного ряда), каждый из которых имеет длину 63 (количество нейронов), это составляет 63×100 градиентов на выборку. Учитывая, что весь набор данных содержит около 4400 отсчетов, мы получаем кубический массив значений градиента размером 4400x63x100. Чтобы выявить различные аспекты чувствительности модели, мы можем усреднить этот массив градиентов по трем измерениям — выборкам, нейронам или положению во входной последовательности. Усреднение градиентов по всем выборкам и всем временным окнам обеспечило одно среднее значение градиента на нейрон. На втором этапе мы исследуем, как чувствительность к количеству спайков нейрона зависит от того, находится ли животное в пределах своего поля места или нет. Поля мест имеют переменную форму и размер, и, кроме того, небольшая часть записанных ячеек не имеет четких полей мест.Кроме того, частота возбуждения и сила градиента сильно различаются между нейронами. Таким образом, мы использовали скорость стрельбы в качестве прокси, чтобы указать близость животного к заданному полю места нейрона — скорость стрельбы максимальна, когда животное находится близко к центру поля места, уменьшаясь по мере удаления от этой точки. Следовательно, после нормализации как скорости срабатывания, так и силы градиентов мы усреднили по всем записанным ячейкам (см. Рис. 6. Градиентный анализ: Чувствительность уменьшается с увеличением активности. (a) Поле размещения примерного нейрона. (b) Поле чувствительности — абсолютные значения градиентов в разных местах для одного и того же нейрона. https: // doi.org / 10.1371 / journal.pcbi.1006822.g006 Мы показали, что последовательная обработка, обеспечиваемая искусственной рекуррентной нейронной сетью (RNN), обеспечивает гибкую методологию, способную эффективно декодировать информацию от популяции нейронов. Более того, поскольку декодер RNN представляет собой нейронную сеть, он представляет собой биологически релевантную модель того, как обрабатывается нейронная информация. В частности, применительно к нейронным данным гиппокампа от свободно движущихся крыс [2] сеть использовала прошлую нейронную активность для повышения точности декодирования положений животных.На двумерной арене открытого поля (1 м x 1 м) декодер RNN смог определить положение со средней ошибкой от 10,3 до 13,1 см для 5 разных крыс. Эти результаты представляют собой заметное улучшение как по сравнению с простым байесовским декодером, использующим плоский априор [14, 16, 29], который основывает свое решение исключительно на подсчете всплесков из одного временного окна, сосредоточенного вокруг момента измерения положения, так и по байесовскому алгоритму. байесовские методы являются оптимальными декодерами при использовании соответствующих априорных значений [41]. Однако в применении к нейронному декодированию трудно определить эти подходящие априорные значения — в результате обычно используются неоптимальные приближения. Следовательно, мы предлагаем, чтобы RNN предлагали практическую методологию для включения последовательного контекста без необходимости выбирать или оценивать конкретные априорные значения для многомерных пространств. Улучшение декодирования 2D-положения, наблюдаемое для RNN, было отражено аналогичными результатами задачи 1D-декодирования с использованием записей гиппокампа, сделанных во время бега животных по 6-метровой дорожке.Здесь снова декодер RNN достиг таких же или лучших результатов, чем байесовские подходы. Используя прошлую нейронную активность в качестве контекстной информации, RNN кажется более устойчивой к шуму, чем два байесовских классификатора. Помимо качества и количества доступных данных, размер ошибки, допущенной декодером RNN, также был замечен в зависимости от расстояния животного от стен и его мгновенной скорости. На более высоких скоростях (выше 10,5 см / с) точность декодирования не снижается, но когда животное неподвижно (ниже 0.5 см / с) погрешность была значительно выше, чем при движении. Мы предполагаем, что в то время как стационарная активность гиппокампа может отражать нелокальную активность, связанную с состояниями резких волн [38]. Помимо более точного декодирования, нейросетевой подход также предоставляет новые средства проведения анализа чувствительности. Хотя анализ чувствительности нокаутного типа может применяться как к байесовским декодерам, так и к декодерам RNN, последний подход также поддерживает градиентный анализ. Два типа чувствительности — нокаут и градиент — взаимосвязаны, но не идентичны.По дизайну нокаут-анализ отвечает, как ведет себя система, если вход полностью удален, а градиентный анализ исследует, как система ведет себя в ответ на небольшие возмущения этого входа. Все процедуры были одобрены Министерством внутренних дел Великобритании с учетом ограничений и положений, содержащихся в Законе о научных процедурах в отношении животных 1986 года. В этом исследовании использовали пять самцов крыс Lister Hooded. Все процедуры были одобрены Министерством внутренних дел Великобритании с учетом ограничений и положений, содержащихся в Законе о научных процедурах в отношении животных 1986 года. Все крысы (330 — 400 г /13 — 18 недель на момент имплантации) получили по два микродвигателя, на каждом из которых был установлен микродвигатель. восемь тетродов из скрученной платино-иридиевой проволоки 17 мкм HM-L (90% и 10%, соответственно; California Fine Wire), нацеленных на правый CA1 (ML: 2. Скрининг проводился после хирургического вмешательства после периода восстановления в течение 1 недели. Система записи Axona (Axona Ltd., Сент-Олбанс, Великобритания) использовалась для сбора данных о единичных единицах и положения (подробности о системе записи и базовом протоколе записи см. В Barry et al (2007). Положение и направление головы Предполагалось, что животные находятся в подвешенном состоянии с помощью видеокамеры для записи местоположения двух светодиодов, установленных на головных столиках животных (50 Гц). Эксперимент проводили в световой период животных. Сначала животные бегали по Z-образной дорожке, возвышающейся над землей на 75 см и шириной 10 см . Две параллельные дорожки Z (190 см каждая) были соединены диагональной секцией (220 см ). Весь трек был окружен простыми черными занавесками без отдаленных намеков.Во время каждой тренировки по треку животные должны были пройти круги по приподнятому Z-образному треку. В частности, животные должны были бежать от начала Arm1 до конца Arm3, останавливаясь на углах и концах дорожки, чтобы получить пищевое вознаграждение. Если животные совершали неправильный поворот на углах, награда удерживалась. Трое животных (R2192, R2198 и R2217) были обучены бегать по дорожке в течение 3 дней перед началом регистрации. После сеанса отслеживания те же животные завершили 20-минутный сеанс случайного поиска пищи в квадратном вольере (1 м x 1 м). Покрытие вольера поощрялось награждением животных подслащенным рисом. Эти записи составляют набор данных, который мы называем задачей 2D-декодирования. Использовались не все записи животных. Глубокое обучение — это класс алгоритмов, которые изучают иерархию представлений или преобразований данных, которые упрощают задачу классификации или регрессии [31, 33].В частности, глубокие нейронные сети, вдохновленные биологическими нейронными цепями, состоят из слоев вычислительных единиц, называемых нейронами или узлами. Глубина означает, что между входом и выходом есть несколько «скрытых» слоев. Настраивая веса связи между своими слоями, нейронная сеть может научиться аппроксимировать функцию из набора примеров, то есть пар связанных входных и выходных данных. В то время как нейронные сети с прямой связью учатся предсказывать выход на основе одного входа, рекуррентные нейронные сети (RNN) могут иметь дело с сериями входов и / или выходов [32, 33]. В частности, рекуррентная сеть может сохранять информацию из предыдущих входов посредством обратных связей (петель между ее блоками). Доступ к прошлой информации может быть полезен для минимизации ошибок при выполнении определенных задач. Такая память прошлых входных данных также означает, что порядок, в котором входные данные представляются в сеть, может изменять возможные прогнозы и, таким образом, интегрировать контекстную информацию с течением времени.Наивная реализация RNN может поддерживать информацию только из нескольких прошлых входов, что позволяет сети обнаруживать только непосредственные тенденции, но не зависимости в длительном масштабе времени. RNN может быть создана для прогнозирования (i) серии выходов на основе серии входов, (ii) серии выходов с учетом только одного входа и (iii) одного выхода с учетом серии входов. Для нашей задачи прогнозирования местоположения нас интересует последнее — учитывая активность гиппокампа (количество спайков) в течение более длительного периода времени, мы стремимся предсказать один набор пространственных координат — местоположение животного. Архитектура RNN, показанная на рис. 7c, используемая в этой работе, состоит из входного слоя (такого же размера, как количество записанных нейронов), за которым следуют два слоя LSTM с 512 узлами, и выходной слой (2 узла, один для каждая пространственная координата x и y ). Рис. 7. Извлечение признаков из пиковых данных и архитектуры нейронной сети. (a) Извлечение последовательности векторов подсчета пиков из данных пиков. Каждый последующий ввод происходит из перекрывающегося периода времени, сдвинутого на 200 мс вперед во времени.(b) Входные данные, которые будет использовать декодер RNN, представляют собой последовательность векторов подсчета пиков из этих временных окон. (c) Сеть, используемая для декодирования, состоит из входного слоя (размер равен количеству записанных нейронов), двух скрытых слоев, содержащих 512 единиц долгосрочной памяти (LSTM), и выходного слоя размером 2 ( x и y). координат). Векторы счетчика пиков вставляются во входной слой один за другим на каждом временном шаге. https://doi.org/10.1371/journal.pcbi.1006822.g007 Особенности нейронных данных, используемых для декодирования, — это количество спайков всех N зарегистрированных клеток (образующих вектор подсчета спайков , как показано на рис. 7a и 7b). В частности, рекуррентная нейронная сеть представлена серией из 100 таких векторов подсчета спайков, соответствующих активности всех ячеек в 100 перекрывающихся временных окнах. Сдвиг между последовательными временными окнами был зафиксирован на 200 мс для всех размеров окна (это означает перекрытие 0% в окнах 200 мс, перекрытие 50% в окнах 400 мс, перекрытие 80% в окнах 1000 мс).Через 100 временных шагов мы считаем активность примерно за 20 секунд. На основе этой серии из 100 векторов подсчета спайков рекуррентная сеть была обучена предсказывать местоположение крысы в центре последнего (100-го) временного окна. Таким образом, каждая последовательность из 100 векторов плюс правильное местоположение крысы в центре последнего временного окна формирует одну точку данных для обучения RNN. Во время процедуры обучения сеть стремится минимизировать целевую функцию, в нашем случае среднеквадратичную ошибку координат.Обучение выполняется для 50 эпох (полные циклы обучающих данных) с использованием постоянной скорости обучения 0,001 и оптимизатора RMSprop (вариант стохастического градиентного спуска, см. Подробное описание в [44]) с размером мини-пакета, равным 64. Все расчеты проводились с использованием заказных скриптов с использованием библиотеки нейронных сетей Keras [45]. Обучение 10-кратной перекрестной проверке заняло около 4 часов на видеокарте GeForce GTX Titan X. Код для обучения моделей RNN можно найти на https: // github.com / NeuroCSUT / RatGPS. Репозиторий также содержит наборы данных (предварительно обработанные в счетчике всплесков и местоположениях на временное окно) и сценарии построения графиков для генерации цифр. Все необходимые данные для заходов на посадку по RNN содержатся в подпапках 1D / data и 2D / data репозитория для Z-трека и открытого поля соответственно. При поиске наилучшей модели рекуррентной нейронной сети мы просканировали несколько архитектур. Первоначально мы экспериментировали с моделями «многие ко многим», которые предсказывают местоположение на временном шаге, и с двунаправленными моделями RNN [46], которые также учитывают будущую активность.В конечном итоге мы приняли подход «многие к одному», который обеспечивал превосходную точность прогнозов (по сравнению с «многие ко многим») и полагался только на прошлую информацию (в отличие от двунаправленного). Мы экспериментировали с рекуррентными модулями LSTM и GRU [43]. Мы сканировали количество повторяющихся слоев в диапазоне (от 1 до 4) и количество единиц на слой в диапазоне (от 128 до 2048). Мы добавили Dropout [47] с вероятностью выпадения {0, 0,2 или 0,5} после каждого уровня LSTM. Мы попробовали оптимизаторы Adam [48] и RMSProp с разной скоростью обучения (10 e −2 до 10 e −4 ) и размерами пакетов (от 5 до 100).Скорость обучения умножалась каждые {1, 5 или 10} эпох с коэффициентом {0,1, 0,5 или 1,0}. Обучаем моделей для 10, 50 и 100 эпох. Мы не использовали раннюю остановку, потому что мы сообщаем о производительности перекрестной проверки и, следовательно, использование набора проверки на любом этапе процесса обучения может привести к завышению результатов. Поскольку количество возможных комбинаций параметров огромно, мы не выполняли полный поиск по сетке, вместо этого мы исключили значения из рассмотрения, если они снижали производительность проверки или увеличивали вычислительные затраты без улучшения модели. Пространственное декодирование также было реализовано с использованием байесовской структуры [14, 29, 49] с учетом 10-кратной перекрестной проверки (см. Также следующий подраздел). В частности, для каждой кратности 90% данных использовалось для создания ratemaps для нейронов гиппокампа — данные спайков и времени пребывания были объединены в квадратные ячейки 2 см, сглажены с помощью ядра Гаусса ( σ = 1,5 ячейки) и рассчитаны скорости путем деления числа всплесков на время пребывания. Обратите внимание, что только для Z-лабиринта позиционные данные были линеаризованы перед биннингом. Затем, используя оставшиеся 10% данных, используя временные окна (от 200 мс до 4000 мс), каждое из которых перекрывается со своими соседями наполовину, мы вычисляем вероятность присутствия животного в каждой пространственной ячейке с учетом наблюдаемых всплесков — матрица апостериорной вероятности [14, 16, 29]. В частности, в течение временного окна (T) выбросы, генерируемые N ячеек места, составляли K = ( k 1 ,…, k i ,…, k N ), где k i было количеством шипов, выпущенных ячейкой i — th .Вероятность наблюдения K во время T для данной позиции ( x ) была взята как: где x обозначает 2-сантиметровые пространственные интервалы, определенные на Z-образной траектории / среде поиска пищи, а α i ( x ) — это скорость стрельбы i — -я -я ячейка в позиции x , получено из ratemaps. В случае простого байесовского декодера, чтобы вычислить вероятность положения животного с учетом наблюдаемых всплесков, мы применили правило Байеса, предполагая плоское априорное положение для положения ( P ( x )), чтобы получить: где R — нормирующая константа, зависящая от T и количества излучаемых выбросов.Обратите внимание, что в этом случае мы не используем историческое положение животных для ограничения P ( x | K ), поэтому оценка вероятности в каждом T не зависит от его соседей. Наконец, позиция была декодирована из апостериорной матрицы вероятности с использованием метода максимального правдоподобия — выбор ячейки с наивысшим значением вероятности. Затем за ошибку декодирования принималось евклидово расстояние между центром декодированной ячейки и центром ячейки, ближайшей к истинному местонахождению животного. Наконец, мы внесли еще два изменения в байесовский декодер с памятью. Сначала для каждого животного P ( x ), вероятность нахождения в положении x , была рассчитана непосредственно из экспериментальных данных для всего испытания, что дает: Во-вторых, следуя [14], мы включили ограничение непрерывности, так что информация о декодированном положении животного на предыдущем временном шаге использовалась для вычисления условной вероятности P ( x t | шипов т , x т −1 ).Где C — нормализующая константа, а normDist — нормальное распределение с центром в декодированной позиции животного на предыдущем временном шаге с сигмой, равной среднему расстоянию, пройденному за временной шаг за предыдущие 15 временных шагов, умноженному на коэффициент масштабирования, который был установлен на 1. для декодирования открытого поля и 5 для линейного трека. Реализации этих двух подходов можно найти в байесовской папке репозитория GitHub https://github.com/NeuroCSUT/RatGPS. Обратите внимание, что данные для MLE и байесовских аппораций должны быть загружены и добавлены в папку Bayesian / Data вручную, так как файлы были слишком большими, их следует добавить в GitHub.Как указано в файлах README в репозитории, данные можно найти через DOI (https://doi.org/10.5281/zenodo.2540921). Сообщаемые ошибки как для байесовского, так и для RNN-подхода измеряются с использованием 10-кратного метода перекрестной проверки, который делит точки данных D между обучающими и проверочными наборами. Из-за перекрытия между последовательными временными окнами случайное назначение точек данных для обучающего и проверочного наборов будет означать, что для большинства проверочных данных в обучающем наборе может быть найдена сильно коррелированная соседняя выборка.Это приведет к искусственно завышенной точности проверки, которая фактически не отражает способность модели обобщать новые, невидимые данные. Вместо этого в нашем анализе первая кратность перекрестной проверки просто соответствует пропуску первых 10% времени записи и обучению модели на последних 90% данных. Вторая кратность, соответственно, назначает вторую десятую записей набору проверки и так далее. Для RNN нам необходимо дополнительно отбросить 99 выборок на каждой границе между обучающим и проверочным наборами.Напомним, что входные данные для RNN представляют собой серию из 100 векторов подсчета всплесков — чтобы избежать перекрытия между обучающими и тестовыми данными, мы удаляем точки данных проверки, которые имеют хотя бы один общий вектор подсчета всплесков с любой точкой данных обучения. Для каждой складки мы обучаем модель на обучающем наборе и вычисляем ошибку на проверочном наборе. Все сообщенные ошибки являются ошибками валидации — ошибками, которые модели допускают для одной десятой данных, которые были исключены из процедуры обучения. Чтобы повысить надежность результатов, мы выполняем 10-кратную процедуру перекрестной проверки несколько раз и сообщаем среднее и медианное значение ошибок.Это делается только для декодера RNN, поскольку байесовский декодер является детерминированным, и повторение процедуры перекрестной проверки несколько раз не требуется. При декодировании местоположений крыс на 2D-арене ошибки предсказания количественно определялись средним евклидовым расстоянием (MED) между предсказанным и истинным положением: где и — местоположения, предсказанные декодером, y и x — истинные местоположения, а N — количество точек данных. Процедура обучения рекуррентных нейронных сетей является стохастической, что может привести к различным решениям с одинаковыми начальными условиями. Мы повторяем 10-кратную перекрестную проверку 10 раз, давая нам 10 независимых прогнозов для каждой точки данных. Мы сообщаем среднее значение ошибок по этим 10 реализациям (а не ошибку усредненного прогноза). Для оценки ошибок координат x ( y ) в приведенной выше формуле использовался только компонент положений x ( y ): В дополнительном эксперименте мы также расшифровываем местоположения крыс на Z-образной дорожке длиной 600 см.Положение крысы на дорожке рассматривается как 1D координата в диапазоне от 0 на одном конце дорожки до 600 на другом конце Z-образной формы. Для получения этих одномерных координат фактические местоположения, извлеченные из изображений с камеры, проецируются на ближайшую точку на Z-образной идеальной траектории. Ошибка прогнозирования модели количественно определяется абсолютным расстоянием между прогнозируемым и истинным положением вдоль этой одномерной координаты. Для анализа нокаута мы устанавливаем активность рассматриваемого нейрона равной нулю во всех точках данных проверки, а затем вычисляем ошибки проверки.Активность не отменяется во время обучения модели, поэтому система не может научиться компенсировать или адаптироваться. Мы повторили эту процедуру нокаута для каждого нейрона по очереди. Градиент функции потерь по отношению к входам был рассчитан с использованием обратного распространения во времени [50], аналогично тому, как находятся градиенты по отношению к весам. Действительно, для обновления весов соединений сети во время обучения алгоритм должен вычислять градиенты функции потерь по отношению к весам [31].Эти градиенты говорят нам, как небольшое изменение конкретного веса повлияет на окончательную ошибку вывода. Здесь мы задаем аналогичный вопрос — насколько небольшое отклонение в определенных входных данных повлияет на окончательные потери. Важно отметить, что, говоря о чувствительности, мы не обращаем внимания на знак градиента, во всех результатах мы используем абсолютные значения (величины) градиентов. Мы вычисляем силу градиента для каждой точки данных набора проверки и отдельно для каждого числа импульсов нейрона для каждой позиции во временном ряду входов T ( T = 100).В результате получается матрица значений градиента D × N × T . Чтобы сделать дальнейшие выводы из значений градиента, нам нужно усреднить или манипулировать этой трехмерной матрицей по различным измерениям. Например, при вычислении нейронов, к которым модель наиболее чувствительна, нам нужно усреднить все точки данных и все временные шаги, поэтому остается одно значение на нейрон. При исследовании взаимосвязи между чувствительностью и положением в поле места (на рис. 6c) нам также необходимо нормализовать количество спайков и величину градиента различных нейронов, чтобы мы могли их агрегировать.Для этого обычно делят количество всплесков на максимальное значение, в результате чего для всех ячеек получают значения от 0 до 1. Однако в случае нейронов с низкой активностью шумность данных означает, что максимальное значение может быть выбросом (у нас может быть максимальное количество 4, тогда как никакое другое значение не превышает 2). Поэтому мы предпочитаем вместо этого делить количество всплесков на 99-й процентиль значений количества всплесков. Некоторые значения оказываются выше 1, но нормализованные распределения значений нейронов с низкой и высокой активностью выглядят более похожими.Мы делаем аналогичную нормировку 99-го процентиля для абсолютных значений градиентов. Для каждой нормализованной скорости стрельбы у нас есть один соответствующий нормализованный размер градиента. Затем мы можем построить график зависимости размера нормализованного градиента от нормализованной скорости стрельбы. Скорость движения основана на расстоянии, пройденном за 200 мс. Первый столбец — это среднее значение ошибок для скоростей в диапазоне [0, 0.5] см / с, второй для (0,5, 1,5] см / с и т. Д. Ошибка наиболее высока, когда крыса не движется или движется очень медленно. Обратите внимание, что скорости в диапазоне 1-2 см / с также могут быть результатом движений головы. На более высоких скоростях точная скорость, похоже, не влияет на точность. Обратите внимание, что столбцы не содержат одинакового количества точек данных. Явные изменения средней ошибки при более высоких скоростях можно отнести к шуму, поскольку мы там меньше точек данных. https://doi.org/10.1371/journal.pcbi.1006822.s001 (TIF) Верхняя строка: цвет показывает, находится ли истинное местоположение точки данных около стены. Нижняя строка: точки окрашены в соответствии с координатой X истинного местоположения точки данных и размером в соответствии с координатой Y. В левом столбце показано, как схемы окраски выглядят в истинных координатах XY. В правом столбце показаны схемы, применяемые к активациям узлов на втором уровне модели RNN при t = 100, уменьшенные до 2D с помощью t-SNE.Обратите внимание, что точки данных с аналогичным истинным местоположением также находятся поблизости в пространстве активности. https://doi.org/10.1371/journal.pcbi.1006822.s002 (TIF) Верхний ряд: точки данных окрашены в соответствии с мгновенной скоростью. Нижний ряд: данные указывают цветом в соответствии с мгновенным направлением движения. В левом столбце показано соответствие между истинным местоположением, скоростью и направлением. В правом столбце схемы окраски применяются к активациям узлов во втором слое модели RNN при t = 100, уменьшенном до 2D с помощью t-SNE.Нет видимого соответствия между активациями RNN ни скоростью, ни направлением. https://doi.org/10.1371/journal.pcbi.1006822.s003 (TIF) a-e) Временные профили относительной важности для 5 выбранных нейронов среди нейронов с наибольшим вкладом согласно градиентному анализу. Обратите внимание, что профили достигают пика на разных временных шагах. е) Временной профиль наименее важного нейрона согласно градиентному анализу. https://doi.org/10.1371/journal.pcbi.1006822.s004 (TIF) Мы благодарим Зураба Бжалава, Сандера Танни и Яана Ару за раннюю работу и полезные обсуждения. Мы также благодарим Джека Келли за полезные обсуждения. Декодирование дисциплин — это процесс повышения уровня обучения учащихся за счет сокращения разрыва между мышлением эксперта и новичка.Начиная с выявления узких мест в обучении по конкретным дисциплинам, он стремится выявить неявные знания экспертов и помочь студентам овладеть умственными действиями, которые им необходимы для успеха на определенных курсах. Шаги в процессе декодирования Мы видим Этот веб-сайт находится в процессе совместной работы всего сообщества Decoding и призван сделать более доступными работу, которая выполняется в рамках этой структуры во всем мире.Мы с нетерпением ждем вашего вклада и предложений. Эта работа основана на кодах исправления ошибок в мозге. Чтобы противодействовать эффекту шума представления, большое количество нейронов участвует в кодировании даже низкоразмерных переменных. Во многих областях мозга средняя частота срабатывания нейронов как функция представленной переменной, называемой кривой настройки, имеет одномодальную форму с центрами в разных значениях, определяя унарный код.Эта диссертация посвящена новому типу нейронного кода, в котором нейроны имеют периодические кривые настройки с различными периодами. Нейроны, которые демонстрируют эту настройку, представляют собой сеточные клетки энторинальной коры, которые представляют собой расположение в двумерном пространстве. Во-первых, мы исследуем взаимную информацию между такими многомасштабными кодами и кодируемой переменной как функцию ширины настроечной кривой. Для декодирования мы рассматриваем модели на основе максимального правдоподобия (ML) и правдоподобной нейронной сети (NN). Для унарных нейронных кодов информация Фишера увеличивается с более узкой настройкой, независимо от метода декодирования.Напротив, для многомасштабного нейронного кода оптимальная ширина кривой настройки зависит от метода декодирования. В то время как узкая настройка оптимальна для декодирования ML, конечная ширина, согласованная со статистикой шума, оптимальна для декодера NN. Это открытие может объяснить, почему фактические кривые настройки нейронов имеют относительно широкую настройку. Затем, мотивированные наблюдением, что многомасштабные коды включают нетривиальное декодирование, мы исследуем алгоритм декодирования, основанный на распространении убеждений (BP), поскольку BP обещает определенный выигрыш в эффективности декодирования.Проблема декодирования сначала формулируется как проблема выбора подмножества на графе, а затем приближенно решается BP. Несмотря на то, что граф имеет много циклов, BP сходится к фиксированной точке после нескольких итераций. Среднеквадратичная ошибка BP приближается к ошибке ML при высоких отношениях сигнал / шум. Наконец, используя многомасштабный код, мы предлагаем схему совместного кодирования канала источника, которая позволяет отдельным отправителям передавать дополнительную информацию по каналам с аддитивным гауссовым шумом без взаимодействия.Приемник декодирует кодовое слово одного отправителя, используя другое в качестве дополнительной информации, и достигает меньшего искажения, используя то же количество передач. Предлагаемая схема предлагает новую структуру для разработки распределенных кодов совместного канала источника для непрерывных переменных. В массиве Галуа Марни: Здравствуйте! Меня зовут Марни Гинзберг из Reading Simplified. Наша миссия — помочь классным учителям упростить обучение чтению и повысить успеваемость учащихся. Итак, сегодня мы собираемся показать вам «Смешивайте по мере чтения». Это супер-простое упражнение, которое так полезно для молодых учеников, чтобы научить их читать и расшифровывать. Это основная стратегия декодирования, которую я использую, чтобы научить детей декодировать, и она экономит так много времени по сравнению со многими другими традиционными подходами к декодированию. Итак, вы готовы? Я собираюсь научить… теперь я воспользуюсь упражнением под названием «Прочтите», в котором мы обучаем стратегии декодирования «Смешивать по ходу». Теперь он уже учится, у него уже неплохо получается Blend As You Go . Но мы собираемся показать вам, как он это делает, и если ему понадобится помощь, отлично. Хорошо, мы удалим это, чтобы приступить к работе. Мы собираемся выбрать слово, слово CVCC, не самое сложное с точки зрения развития или фонематики. Марни:… вы должны прочитать это, прежде чем писать. Нет, прежде чем вы это напишете … вы должны это прочитать. Я не знаю, что там написано … а вы? Дочерний: Поля? Марни: Может быть, но что еще это может быть (нажатие на «е»)? Ребенок: (произнося слово) F… e… .l… .t… .Чувствовал? Марни: «Я пощупал лягушку». Хорошо, я хочу, чтобы вы выбрали один маркер. Который из? Он может написать это — каждый звук, как он произносит каждый звук, — но ему нужно выбрать один, прежде чем он сможет это сделать. Ребенок: Я просто не знаю, в какой из них, и хочу сыграть в крестики-нолики. Марни: О, крестики-нолики — это забавная игра. Мы можем играть в крестики-нолики, вставляя слова в каждый квадрат, и он читает их, прежде чем приступить к игре, но прямо сейчас я просто хочу показать им, как вы это делаете. Вы можете им показать? Детский: Хорошо. Какой выбрать? Какая из них лучше? Марни: Хмм… есть ли здесь у кого-нибудь голосование? О, я думаю, твой папа смотрит. Какой цвет он бы хотел, чтобы вы выбрали? Ребенок: Не знаю. Марни: Давай с синим. Хорошо? Марни: Ладно, произнеси звуки по мере написания. Детский: (вслух) fff… .eee… .lll… ttt… Feee …… Марни: Вы были правы, это / ě / — войлок. «Я почувствовал твою руку; твою руку. » Ребенок: Я думал, что это… iiilllttt .. Marnie: Верно, это может быть / ĭ /, но в этом слове это / ě /. Итак, он применил стратегию «Смешивайте при чтении» , чтобы прочитать это.Он написал это и сказал каждый звук, поэтому он сегментировал его, что является еще одним подходом, который помогает стать хорошим читателем. Теперь произнеси звуки и сотри. Дочерний: (стирание) ffellttt… Марни: Хорошо, это был CVCC, и он смог это сделать. У него совсем не было проблем со смешиванием, поэтому я сделаю это немного сложнее; Я сделаю слово CCVC. (ребенку) Теперь тебе нужно дождаться моей очереди, хорошо. Хорошо, хорошо, я хочу, чтобы моя очередь, хорошо, так что поехали, нет, я думаю, я буду использовать ваши цвета, так как вам нравится этот цвет, и он также темнее. Детский: curllsssss. Марни: Да, может быть. Что еще это могло быть? Детский: Крест? Марни: Ах, крест! Это же крест, правда? Детский: Cr… o… ..o… .ss…. Марни: Вы хотите зеленый? Потому что это лучше, чем фиолетовый. Детский: О… ссссс… ой…. Марни: Не очень хорошо работает. Я просто избавлюсь от этого фиолетового./ crŏss / Детский: Cr… .o… .sssss… Marnie: Передавайте привет, если вы здесь и выполнили «Смешивание по мере чтения». Или, если вы просто видите это впервые, я хочу услышать от вас. Скажи привет; расскажи нам, откуда ты. Хорошо, что нам делать, прежде чем мы закончим, вы должны сыграть в игру стирания. Я тебя побью. Детский: Cro… .sss… Марни: Он сегментирует, получает дополнительную практику фонематической сегментации, когда пишет, хорошо. Итак, CCVC дался вам легко, так что я попробую бросить ему вызов другим. Детский: CCCV? Марни: Верно, CCVCC, давайте посмотрим, смогу ли я найти один из них. Хорошо, я думаю, что нашел, не делайте этого, потому что у вас не будет места для своего слова. Детский: St… aaaannn… .d. Стоять. Марни: Да, что это значит? Детский: Стойка, вроде… она… Marnie: Нравится? Это больше похоже на звук / ă /.Прежде чем писать, давайте удостоверимся, что вы… Детский: Стенд. Стоять. Стоять. Марни: Да! Вставать. Детский: / St… an / Марни: / Ă /… сама по себе, / ă / Ребенок: Annn… ..d. Стоять. Марни: Очень мило! А слово… Детский: Стенд. Марни: Давайте сотрем! /Стоять/. Отлично. Итак, вы слышали, как он сложил эти звуки?… / Ssssttaaaannnd /. Он не пошел… / S / / t / / a / / n / / d / и потом попытался разгадать слово. Он собрал звуки, когда пошел , и это здорово! Посмотрим, возможно, мне придется снова бросить вам вызов! Хм, хорошо, у меня есть вызов. Мне нужно стереть его, чтобы освободить место, ты такой быстрый! Ребенок: St… .rrr… ..aaannnnddd… .Strand. Марни: Угу. Как прядь волос. Детский: Strand. Марни: Strand.Хорошо, произноси звук по ходу дела. О, я снова брошу тебе вызов, я сотру это. Ооо, прядь. Хорошо, он может это сделать, когда не видит этого? Он должен слышать звуки. Strand. Как прядь волос. Хорошо, позвольте мне послушать, вы говорите… Детский: Ssstttt…. Марни: Хорошо. Что это? Ага. Str…. ты забыл один звук. Ребенок: Ой, забыл. Ррррр… .ссст..рррр… .аааааанннннддддд. Марни: Вау! Дамы и господа, наоборот — О, вы делаете капитал / D /? Дамы и господа, он получил «прядь»? Да, он сделал! Woohoo !! Ладно, дайте всем пять! Марни: (смеется) Нет, спасибо. Ребенок: Теперь я проведу линию. Marnie: Итак, вы можете идти, вы проделали отличную работу, вы прошли самый сложный уровень, который у меня есть! Детский: St …… r… aaannnndd. Strand. Марни: Strand. Большое спасибо, что пришли, сегодня вы хорошо поработали! Он также работает над звуком Ă Ребенок: Теперь мне нужно это достать! Марни: Да ладно, угощайся.Итак, он закончил! Таким образом, после участия в нашем «Пятидневном испытании на повышение уровня ваших читателей» в ноябре, когда он не знал коротких гласных, он теперь освоил короткие гласные с помощью Switch It и Read It в тексте для чтения с в основном декодируемыми шаблонами, которые были в соответствии с тем, на что он нацелился в то время. Затем он перешел на Advanced Code или Advanced Phonics, например на звук / oa / во всех его вариантах написания. Он заучивает ключевое предложение: « Иди домой, покажи лодку Джо », и это помогает ему запоминать наиболее частые варианты написания звука / oa /. Потом сделал / ее /. « Он видит многих из них каждый год. ” Это еще одно предложение / ee /, которое помогает ему запомнить такие ключевые варианты написания, как double-e и «ea», и многие … / ee / in / many /. И вот он только сегодня начал звук / ay /, но я также хотел просто проверить, как проходит его чистое смешение с действительно сложными словами CCVCC, а также проверить его короткие гласные. Итак, изначально он хотел выбрать долгий гласный звук, и это нормально.Сейчас это нормально, поскольку мы учим его долгим гласным. Ему нужно будет разработать стратегию, еще одну стратегию декодирования Flex It. С помощью Flex It он пробует один звук, и если он не работает… может быть, это слово было «песок», и он сказал / saind /. Это было не так, но что-то в этом роде, тогда что ж, / saind / не работает, переверните это / ay / и попробуйте другой звук. И вот почему Switch It так полезен, потому что он развил ухо для поиска проблемы — извлечения проблемного звука и добавления нового звука. Итак, то, что он практиковал, было «Смешивание при чтении», и он неплохо в этом разбирался, так что вы не видели, как я научил его делать это на ходу, но я хочу, чтобы вы учли, что такой подход спасет вас время, особенно с вашими борцами. Итак, скажите, у вас есть это слово («солнце»). Что говорят делать многие программы для чтения? Говорят научить … сказать звук сегментированный мод. / S / / ŭ / / n /, а затем вернитесь и попробуйте собрать все вместе.Солнце. Что ж, это работает для некоторых детей, но это не надежная стратегия декодирования. Особенно если у них хорошие воспоминания, они все это могут запомнить. Я думаю, что то, что происходит часто, даже если они говорят / s / / u / / n / в своей голове, они складывают звуки по ходу дела. И на самом деле это самая умная стратегия, и я хочу попросить вас, ребята, научить своих учеников. Опять же, особенно новички или борцы. Итак, вместо того, чтобы идти / s / / u / / n /, мы фактически начинаем с самого начала и соединяем первые два звука.То, что у вас есть, / sssss / / uuuu / / Suuuuu / И вы держите гласную, / sssuuuuu / / n /. Если ученик может добраться до этого среднего гласного — это действительно сложная часть — если он может столько смешать и удержать этот звук… / ssuuuuuuu /, то добавить последний довольно легко. А затем вы переходите к более сложным словам и продолжаете побуждать учащихся смешивать их по мере чтения. Итак, это слово из CVC, которое фонематически проще всего. Следующий уровень фонематического вызова — CVCC.Это похоже на слово «помощь», которое он сделал сегодня. Итак, снова попытайтесь заставить ученика перейти к гласной. / Heeeeeeeeeellllllppppp / Вы держите гласную и согласную / hellllllllll / и постепенно раскрываете согласные, так что ученик Смешивает при чтении ; это ключевая стратегия декодирования здесь. Я знаю, что это так просто и может показаться, что это не так уж и важно, но я считаю, что это быстрое решение для детей, которые испытывают трудности. В общем, сделали «солнышко» для ВАХ.Теперь это CVCC, это немного сложнее, чем «солнце», но мы можем сделать его еще сложнее. Если вы поставите две согласные в начале, это будет следующий уровень проблемы фонематического развития. Итак, давайте сделаем это. Опять же, вместо классического подхода «/ s / / p / / ŏ / / t /. Какое слово?» Вы хотите, чтобы они были Смешивать по мере чтения с самого начала. Сначала вы просите их соединить эти первые два звука.Хорошо, соедините эти первые два звука. / С / / п /. Теперь, может быть, они говорят «/ s / / p /» и не могут понять. В этот момент вы просто говорите, что все в порядке, позвольте мне вам помочь. Я слышу / Sp /, складываю его вместе / Sp / и затем перехожу к этому звуку, и если вы это сделаете, они, вероятно, смогут вставить / ŏ / в / spŏhhhhh /. Я подержу его при себе, притворившись, что я с ребенком, / spŏ– / / t /, и тогда они поймут слово. Итак, это стратегия декодирования «смешивать по мере чтения» с чуть более сложным словом. Когда две согласные находятся в начале, смешивать их сложнее. Так же, как когда дети неправильно говорят «спагетти», а они говорят «сисгетти» или «писгетти». Это потому, что согласные в начале звука слова труднее всего говорить и читать. Хорошо, мы перейдем на новый уровень вместе с вами. Если трудно поставить их в начало, еще труднее поставить их в начало и конец. «стенд» Хорошо, это был пример «стоять», но, может быть, я сделаю еще один. Это слово CCVCC, и оно является самым сложным с точки зрения развития только с фонематической точки зрения. Мы по-прежнему используем короткие гласные, но ученику очень трудно справиться со всеми этими сочетаниями согласных. Итак, вы бы попросили своего ученика сложить первые два звука вместе / s / / t / / st / / ŏ / Удерживайте. / sssstooooooommmmmm / / п / ох топать. И это «Смешивайте по мере чтения» — очень простой, но важный компонент, которого не хватает многим детям. Я считаю это стратегией №1 для начинающих читателей. Это подход, который я хочу, чтобы они использовали, когда они наталкиваются на неизвестное слово. Некоторые люди говорят: ну, это просто не работает из-за всех неровностей в английском языке. И это правда, неровности усложняют задачу, но если вы будете руководить ими в небольшой группе, тогда они смогут добиться успеха. И если вы также контролируете текст, чтобы они не видели слишком много неправильных слов на начальном этапе, когда они только учатся этому подходу, тогда они могут добиться успеха. Вы могли вспомнить, что он написал это слово, а я написал / sh / по орфографии, я написал его другим цветом, потому что я хотел, чтобы он понял, что это одна единица, как если бы он произносил это слово, произнесите слово «толстый», я бы хотел, чтобы он увидел, что / th / — это один звук, а / ck / — это один звук, поэтому он не сказал бы / t / / h /, но он бы увидел в этом единица — «толстая».” Вот как вы можете помочь им сделать смесь по мере чтения, когда вы подойдете к некоторым из более сложных вещей нашего языка. В этом нет ничего необычного, но вот как можно справиться с этими согласными диграфами. Итак, это Blend As You Read, здесь от Reading Simplified. Это стратегия номер один, которую я использую с детьми всех возрастов, даже с детьми, которые читают в средней школе. Недавно у меня была ученица, которая учится в четвертом классе, и она могла читать материалы для седьмого класса, но она все еще боролась в школе и допускала ошибки в чтении.Ее произношение, пропуск слов, пропуск слов и некоторые небрежные ошибки, которые не нравились ее матери, а также ее учитель сказал, что она не понимает, и, о чудо, ее Blend As You Read была очень-очень плохой, что особенно важно когда вы читаете многосложные слова. / В / / Tell / Вы хотите использовать тот же подход, подход «Смешивание по мере чтения», который используется, когда учащийся читает многосложные слова. Я называю это Blended By Chunk. Итак, они попробовали бы первый кусок … / In / / Intell / Итак, они уже смешали эти два вместе / Intella / Intelligent. Вместо / i / / n / / t / / e / / l / Blend As Your Read также работает на многосложном уровне. У этой молодой девушки был такой пробел в декодировании и смешивании, что, когда мы работали над этим заданием, Switch It и парой других вещей, таких как Sort It, она очень быстро прыгнула вперед. После шести занятий ее словесная атака или способность читать бессмысленные слова поднялась на два уровня выше, и это было во многом из-за этой стратегии, а также стратегии Switch It. Так что, если вы собираетесь сюда и еще не пробовали эту стратегию, я буду рад, если вы попробуете. Более подробная информация о Read It содержится в записи блога. В упражнении «Прочтите это» мы обучаем стратегии «Смешивание по мере чтения», поэтому ученик может использовать эту стратегию с возможностями Word Work, но, конечно же, на самом деле мы хотим, чтобы они перенесли ее в реальное чтение, и это моя основная мысль сегодня. Если вы видели, как этот мальчик в предыдущих видеороликах учился делать Switch It, то прочтите сегодня, мы демонстрируем second вещь, которую он выучил, чтобы помочь ему как читателю.Стратегия «Читай и смешивай по мере чтения» — второй по важности инструмент в моем арсенале или в моем арсенале, позволяющий быть эффективным учителем чтения. Спасибо за настройку. Если у вас возникнут вопросы, дайте мне знать. Кроме того, если вы думаете, что это будет полезно для коллеги, я хотел бы, чтобы вы переслали ему этот пост, чтобы они могли получить доступ к этой информации. Если вы думаете, что эта информация необычна и может быть полезна, возможно, некоторые из ваших коллег тоже. Эффективное нейронное декодирование собственного местоположения с глубокой рекуррентной сетью
Abstract
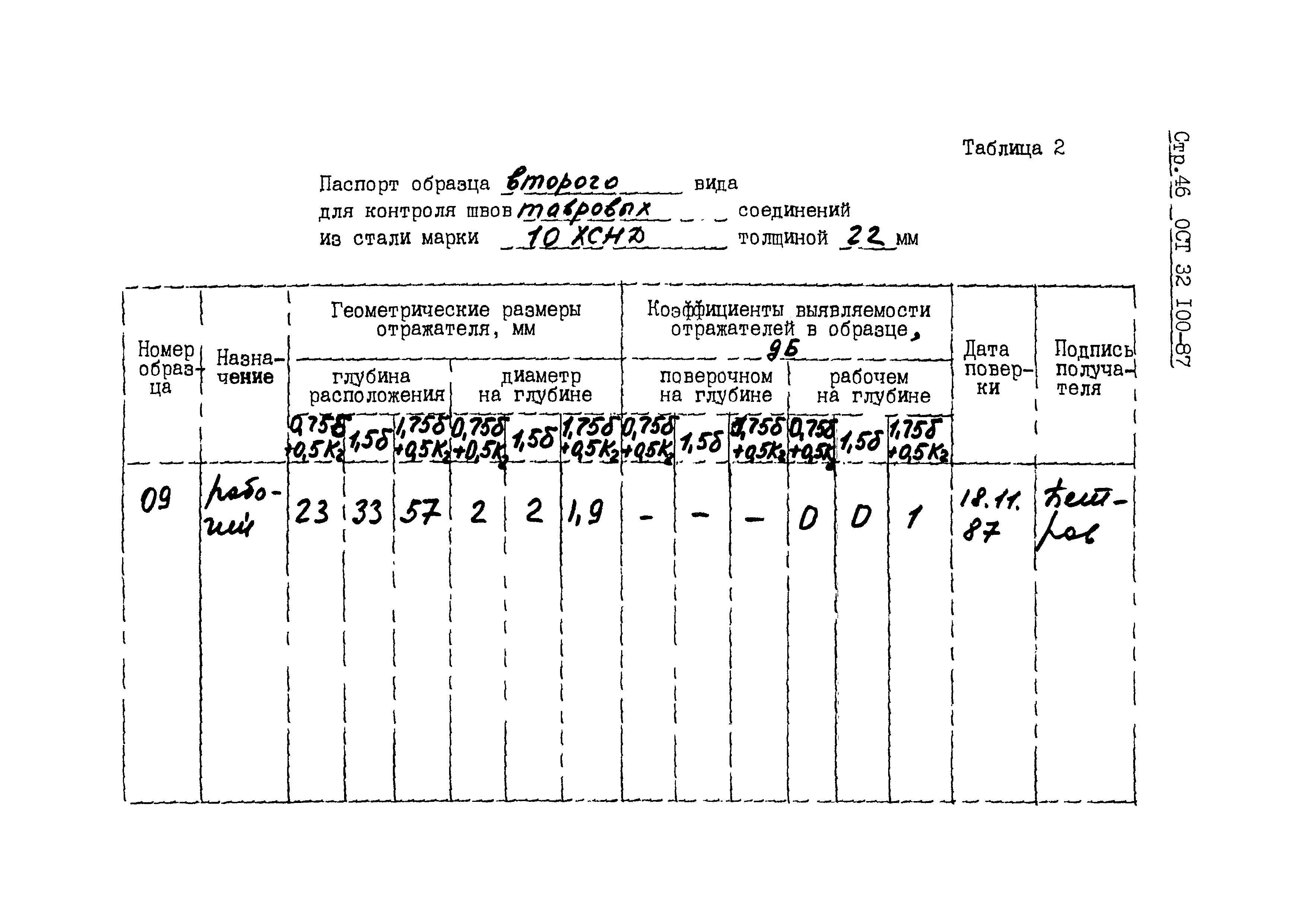 Точность этого декодирования устанавливает нижнюю границу количества информации, которую популяция гиппокампа передает о местонахождении животного.В этой работе мы используем новый декодер рекуррентной нейронной сети (RNN), чтобы сделать вывод о местонахождении свободно движущихся крыс по единичным записям гиппокампа. RNN — это биологически правдоподобные модели нейронных цепей, которые учатся включать соответствующий временной контекст без необходимости делать сложные предположения об использовании предшествующей информации для прогнозирования текущего состояния. При расшифровке положения животных по подсчету спайков в 1D и 2D-средах мы показываем, что RNN последовательно превосходит стандартный байесовский подход с плоскими априорными точками или с памятью.Кроме того, мы также провели ряд анализа чувствительности декодера RNN, чтобы определить, какие нейроны и участки возбуждающих полей оказали наибольшее влияние. Мы обнаружили, что применение RNN к нейронным данным позволяет гибко интегрировать временной контекст, обеспечивая повышенную точность по сравнению с более широко используемыми байесовскими подходами и открывает новые возможности для исследования нейронного кода.
Точность этого декодирования устанавливает нижнюю границу количества информации, которую популяция гиппокампа передает о местонахождении животного.В этой работе мы используем новый декодер рекуррентной нейронной сети (RNN), чтобы сделать вывод о местонахождении свободно движущихся крыс по единичным записям гиппокампа. RNN — это биологически правдоподобные модели нейронных цепей, которые учатся включать соответствующий временной контекст без необходимости делать сложные предположения об использовании предшествующей информации для прогнозирования текущего состояния. При расшифровке положения животных по подсчету спайков в 1D и 2D-средах мы показываем, что RNN последовательно превосходит стандартный байесовский подход с плоскими априорными точками или с памятью.Кроме того, мы также провели ряд анализа чувствительности декодера RNN, чтобы определить, какие нейроны и участки возбуждающих полей оказали наибольшее влияние. Мы обнаружили, что применение RNN к нейронным данным позволяет гибко интегрировать временной контекст, обеспечивая повышенную точность по сравнению с более широко используемыми байесовскими подходами и открывает новые возможности для исследования нейронного кода.
Информация об авторе

 В частности, данные, необходимые для байесовских декодеров, доступны в репозитории Zenodo (https://doi.org/10.5281/zenodo.2540921), а данные для декодеров RNN доступны по адресу (https://github.com/NeuroCSUT/RatGPS ). Весь код также доступен по адресу (https://github.com/NeuroCSUT/RatGPS).
В частности, данные, необходимые для байесовских декодеров, доступны в репозитории Zenodo (https://doi.org/10.5281/zenodo.2540921), а данные для декодеров RNN доступны по адресу (https://github.com/NeuroCSUT/RatGPS ). Весь код также доступен по адресу (https://github.com/NeuroCSUT/RatGPS).
Введение
 воспоминания [2]. Поэтому неудивительно, что, имея информацию об активности популяции клеток места, можно с относительно высокой степенью точности расшифровать местоположение животного [13, 14].
воспоминания [2]. Поэтому неудивительно, что, имея информацию об активности популяции клеток места, можно с относительно высокой степенью точности расшифровать местоположение животного [13, 14].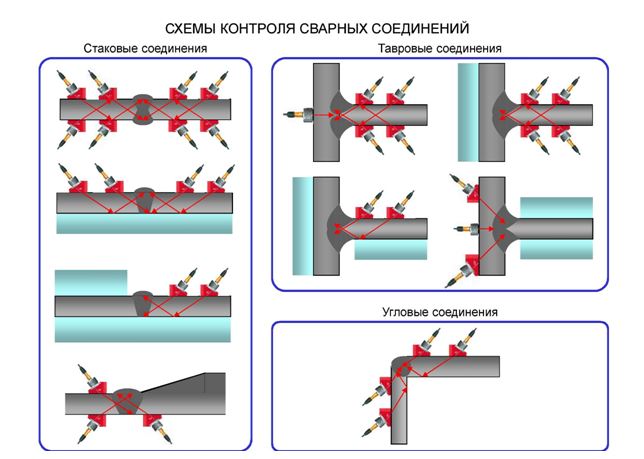 Несмотря на то, что переназначение происходит быстро в новой среде, вновь сформированные огненные поля продолжают уточняться во время последующего опыта, процесс, который, кажется, сохраняется в течение нескольких часов [10, 13, 22, 23]. Известно, что даже в знакомой среде, которую животные посещали много раз, пространственная активность клеток места демонстрирует постепенные изменения, которые могут привести к генерации различных пространственных кодов [23–26], которые могут быть важны для кодирования целевых местоположений [27]. ] или другие непространственные переменные [28].Таким образом, хотя активность гиппокампа предоставляет значительную информацию о само-местонахождении животного, представление является динамическим: накапливает изменения и иногда кодирует другие переменные, как пространственные, так и непространственные.
Несмотря на то, что переназначение происходит быстро в новой среде, вновь сформированные огненные поля продолжают уточняться во время последующего опыта, процесс, который, кажется, сохраняется в течение нескольких часов [10, 13, 22, 23]. Известно, что даже в знакомой среде, которую животные посещали много раз, пространственная активность клеток места демонстрирует постепенные изменения, которые могут привести к генерации различных пространственных кодов [23–26], которые могут быть важны для кодирования целевых местоположений [27]. ] или другие непространственные переменные [28].Таким образом, хотя активность гиппокампа предоставляет значительную информацию о само-местонахождении животного, представление является динамическим: накапливает изменения и иногда кодирует другие переменные, как пространственные, так и непространственные.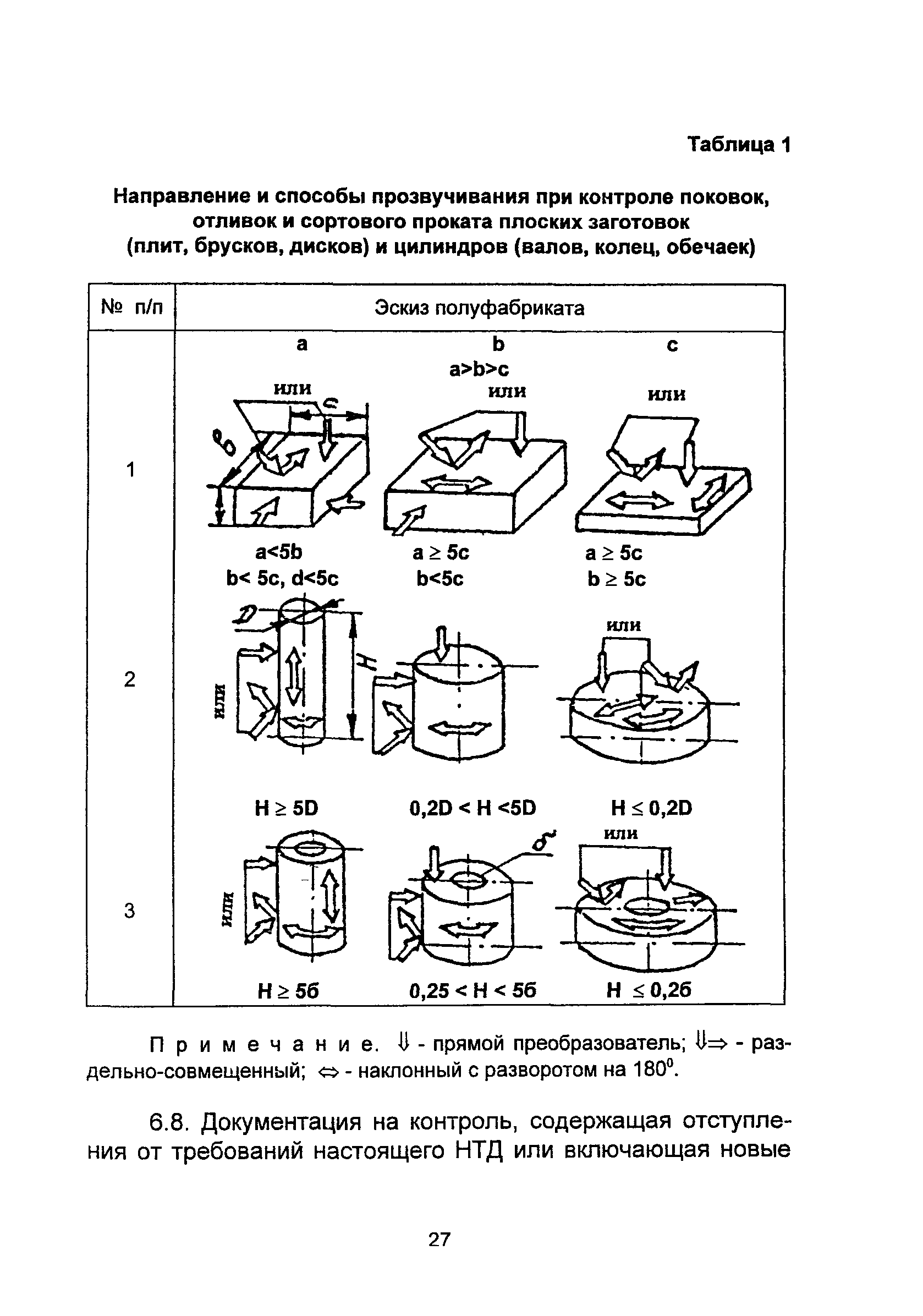 В случае клеток места в методологиях декодирования обычно применяется байесовская структура для вычисления распределения вероятностей по положению животного с учетом наблюдаемых нейронных данных [14, 16, 29]. Затем декодирование для конкретного местоположения выполняется с помощью оценщика максимального правдоподобия, применяемого к распределению вероятностей. Однако точность байесовских методов зависит от точной информации об ожидаемой активности нейронов. Для локальных клеток активность, регистрируемая в течение десятков минут, обычно используется для оценки скорости активации каждой ячейки в различных точках вольера животного, при этом предполагается, что мгновенные скорости демонстрируют динамику Пуассона.Однако по причинам, изложенным выше, неясно, можно ли таким образом моделировать активность гиппокампа. Действительно, известно, что вариабельность скоростей активации клеток места значительно превышает ожидаемую от процесса Пуассона [30]. Таким образом, вполне вероятно, что байесовские методы, применяемые в настоящее время, не обеспечивают точного отражения точности, с которой гиппокамп кодирует свое местоположение.
В случае клеток места в методологиях декодирования обычно применяется байесовская структура для вычисления распределения вероятностей по положению животного с учетом наблюдаемых нейронных данных [14, 16, 29]. Затем декодирование для конкретного местоположения выполняется с помощью оценщика максимального правдоподобия, применяемого к распределению вероятностей. Однако точность байесовских методов зависит от точной информации об ожидаемой активности нейронов. Для локальных клеток активность, регистрируемая в течение десятков минут, обычно используется для оценки скорости активации каждой ячейки в различных точках вольера животного, при этом предполагается, что мгновенные скорости демонстрируют динамику Пуассона.Однако по причинам, изложенным выше, неясно, можно ли таким образом моделировать активность гиппокампа. Действительно, известно, что вариабельность скоростей активации клеток места значительно превышает ожидаемую от процесса Пуассона [30]. Таким образом, вполне вероятно, что байесовские методы, применяемые в настоящее время, не обеспечивают точного отражения точности, с которой гиппокамп кодирует свое местоположение.
 Кроме того, проверка обученной сети позволила нам определить как относительную важность отдельных нейронов для точного декодирования, так и места, в которых они были наиболее информативными. Таким образом, точность RNN не только устанавливает новый предел для количества информации о собственном местоположении, закодированной с помощью ячеек места, но в более общем плане эта работа предполагает, что RNN обеспечивают полезный подход для нейронного декодирования и предоставляют средства для исследования нейронных сетей. код.
Кроме того, проверка обученной сети позволила нам определить как относительную важность отдельных нейронов для точного декодирования, так и места, в которых они были наиболее информативными. Таким образом, точность RNN не только устанавливает новый предел для количества информации о собственном местоположении, закодированной с помощью ячеек места, но в более общем плане эта работа предполагает, что RNN обеспечивают полезный подход для нейронного декодирования и предоставляют средства для исследования нейронных сетей. код. Результаты
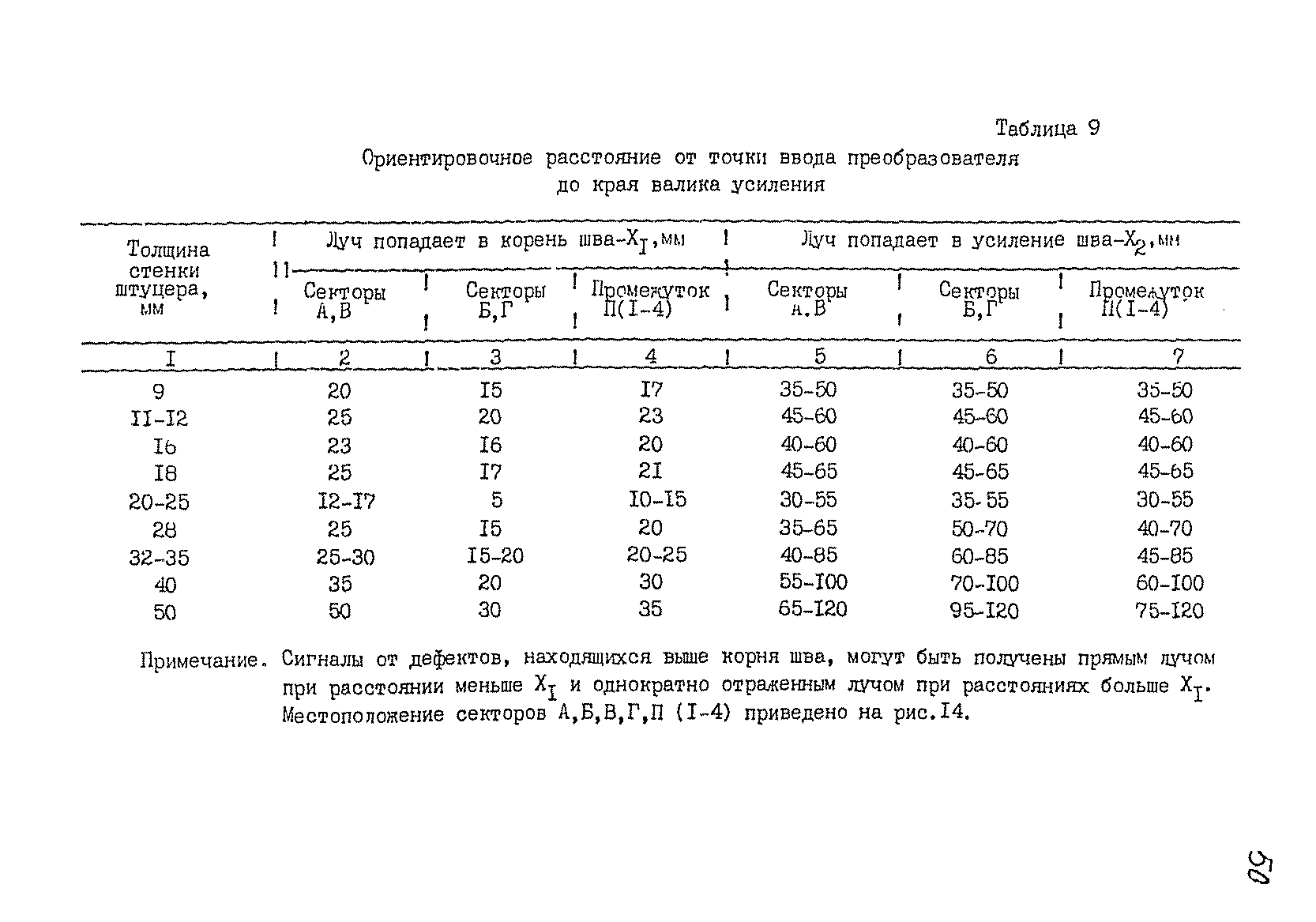 Байесовский анализатор с памятью [14] использует априорную информацию на основе собственного местоположения и скорости движения, декодированные из предыдущих временных шагов (память), а также информацию о местах, которые животное наиболее часто посещает, и объединяет их с вероятностью, рассчитанной на основе пик считается в текущем временном окне.
Байесовский анализатор с памятью [14] использует априорную информацию на основе собственного местоположения и скорости движения, декодированные из предыдущих временных шагов (память), а также информацию о местах, которые животное наиболее часто посещает, и объединяет их с вероятностью, рассчитанной на основе пик считается в текущем временном окне.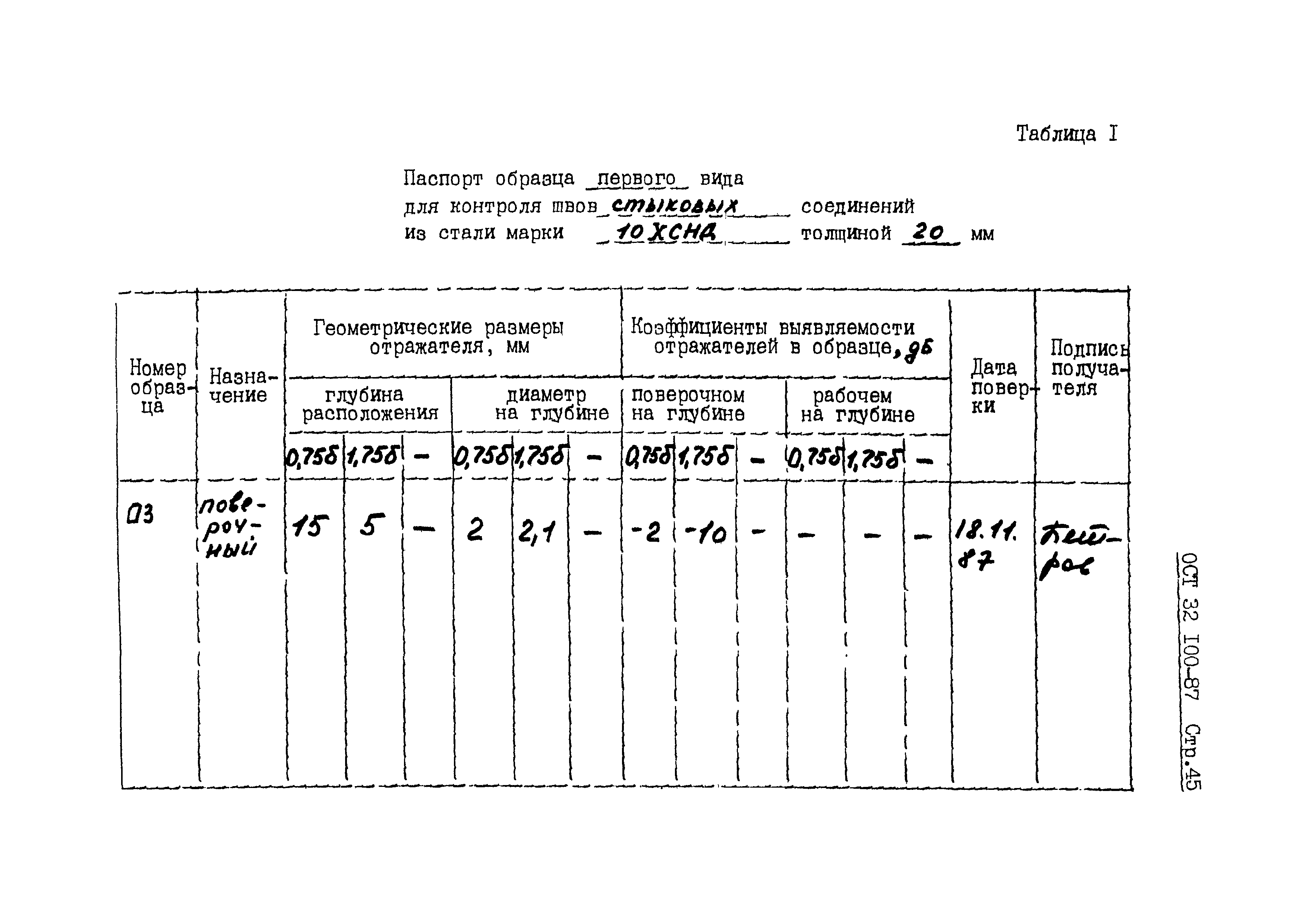 Направление изменения можно найти, вычислив градиент потерь по каждому параметру.
Направление изменения можно найти, вычислив градиент потерь по каждому параметру. Высокоточное декодирование собственного местоположения в 2D-среде
 Крыса R2192 дала наибольшее количество одновременно регистрируемых нейронов гиппокампа (n = 63). Поскольку ожидается, что количество зарегистрированных нейронов будет коррелировать с точностью декодирования, мы сначала сосредоточились на этом конкретном животном.
Крыса R2192 дала наибольшее количество одновременно регистрируемых нейронов гиппокампа (n = 63). Поскольку ожидается, что количество зарегистрированных нейронов будет коррелировать с точностью декодирования, мы сначала сосредоточились на этом конкретном животном.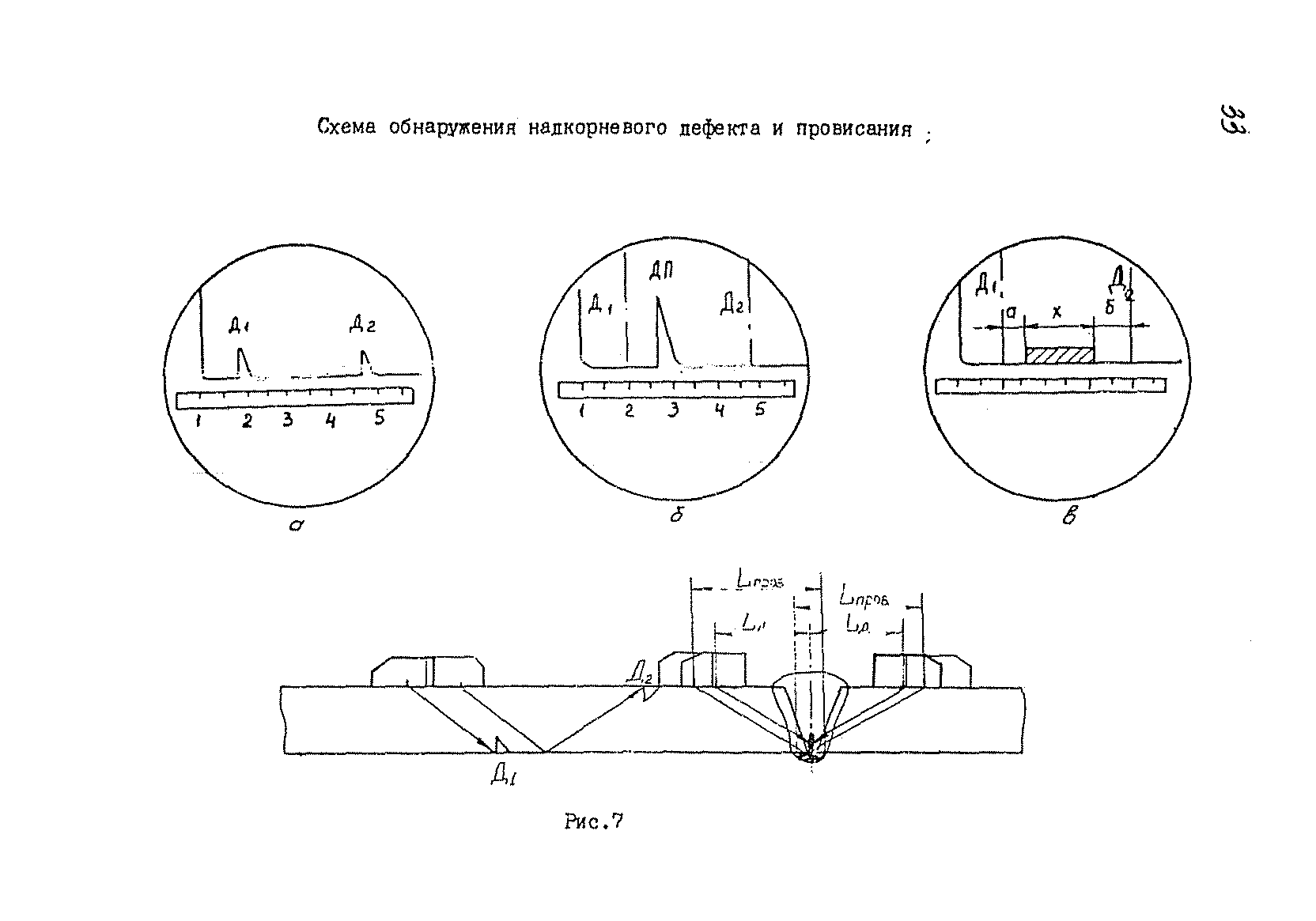
 Показанные результаты относятся к животному R2192.
Показанные результаты относятся к животному R2192. Самая низкая средняя ошибка декодирования, достигнутая с помощью простого байесовского декодера, составила 12,00 см (на 17,9% выше, чем для RNN; эта точность была получена с несколькими различными размерами окон), самая низкая средняя ошибка составила 15,83 см с окном 2800 мс. Байесовский декодер с априорными данными, основанными на исторической активности животного, был более точным, чем наивный байесовский подход, но все же был значительно менее точным, чем RNN (самая низкая средняя ошибка декодирования составляла 15,46 см с окнами 2000 мс, а самая низкая медиана 11.31 см с окнами 1400 мс).
Самая низкая средняя ошибка декодирования, достигнутая с помощью простого байесовского декодера, составила 12,00 см (на 17,9% выше, чем для RNN; эта точность была получена с несколькими различными размерами окон), самая низкая средняя ошибка составила 15,83 см с окном 2800 мс. Байесовский декодер с априорными данными, основанными на исторической активности животного, был более точным, чем наивный байесовский подход, но все же был значительно менее точным, чем RNN (самая низкая средняя ошибка декодирования составляла 15,46 см с окнами 2000 мс, а самая низкая медиана 11.31 см с окнами 1400 мс). Точно так же байесовский декодер с памятью включает прошлую активность для формирования информированного предшествующего, но делает это заранее определенным образом, будучи менее гибким, чем RNN.Также обратите внимание, что подход RNN достигает своих лучших результатов для более коротких временных окон, чем байесовские подходы (см. Также Таблицу 1 для получения результатов об оптимальном размере окна для других животных). Мы предполагаем, что эффективное использование контекстной информации RNN помогает ей преодолеть стохастический шум при подсчете всплесков, полученном для более коротких временных окон.
Точно так же байесовский декодер с памятью включает прошлую активность для формирования информированного предшествующего, но делает это заранее определенным образом, будучи менее гибким, чем RNN.Также обратите внимание, что подход RNN достигает своих лучших результатов для более коротких временных окон, чем байесовские подходы (см. Также Таблицу 1 для получения результатов об оптимальном размере окна для других животных). Мы предполагаем, что эффективное использование контекстной информации RNN помогает ей преодолеть стохастический шум при подсчете всплесков, полученном для более коротких временных окон. 2a).
2a).
 Однако RNN была значительно более устойчивой к небольшим размерам выборки, декодируя с ошибкой 30,9 см только с 5 нейронами по сравнению с ошибкой 46,0 см для байесовского декодера (рис. 2b).
Однако RNN была значительно более устойчивой к небольшим размерам выборки, декодируя с ошибкой 30,9 см только с 5 нейронами по сравнению с ошибкой 46,0 см для байесовского декодера (рис. 2b). Результаты на уровне популяции в 2D и 1D средах
 3a и 3b). Интересно, что, несмотря на то, что в некоторых записях содержится всего 26 или 33 ячейки, точность декодирования с использованием RNN примерно одинакова. Во всех случаях результаты среднего и медианного декодирования от декодера RNN превзошли как стандартный байесовский подход, так и байесовский подход с памятью.
3a и 3b). Интересно, что, несмотря на то, что в некоторых записях содержится всего 26 или 33 ячейки, точность декодирования с использованием RNN примерно одинакова. Во всех случаях результаты среднего и медианного декодирования от декодера RNN превзошли как стандартный байесовский подход, так и байесовский подход с памятью. Как и раньше, мы применили RNN и байесовские декодеры к 10-кратной перекрестной проверке данных, выбирая в каждом случае оптимальный размер временного окна (Таблица 1). Декодер RNN значительно превзошел два байесовских декодера во всех 5 наборах данных при сравнении средних ошибок (рис. 3c).В 2D-задаче наибольшая возможная ошибка составила 141,7 см (если прогнозируемое местоположение находится в углу, диагонально противоположном истинному местоположению), тогда как в 1D-задаче она составляет 600 см (если прогнозируется противоположный конец трека). В задаче 1D небольшое количество очень больших ошибок приведет к увеличению средней ошибки, тогда как медиана будет меньше затронута (рис. 3c и 3d). Изучая средние ошибки, мы обнаружили, что RNN превосходит байесовские декодеры во всех случаях. Однако для четырех из пяти животных разница в ошибке была относительно небольшой (рис. 3d).Для пятой крысы с наименьшим количеством записанных ячеек (R2117, n = 40) RNN явно превосходила байесовские подходы, имея среднюю ошибку декодирования, которая была почти вдвое меньше, чем у двух типов байесовских декодеров.
Как и раньше, мы применили RNN и байесовские декодеры к 10-кратной перекрестной проверке данных, выбирая в каждом случае оптимальный размер временного окна (Таблица 1). Декодер RNN значительно превзошел два байесовских декодера во всех 5 наборах данных при сравнении средних ошибок (рис. 3c).В 2D-задаче наибольшая возможная ошибка составила 141,7 см (если прогнозируемое местоположение находится в углу, диагонально противоположном истинному местоположению), тогда как в 1D-задаче она составляет 600 см (если прогнозируется противоположный конец трека). В задаче 1D небольшое количество очень больших ошибок приведет к увеличению средней ошибки, тогда как медиана будет меньше затронута (рис. 3c и 3d). Изучая средние ошибки, мы обнаружили, что RNN превосходит байесовские декодеры во всех случаях. Однако для четырех из пяти животных разница в ошибке была относительно небольшой (рис. 3d).Для пятой крысы с наименьшим количеством записанных ячеек (R2117, n = 40) RNN явно превосходила байесовские подходы, имея среднюю ошибку декодирования, которая была почти вдвое меньше, чем у двух типов байесовских декодеров.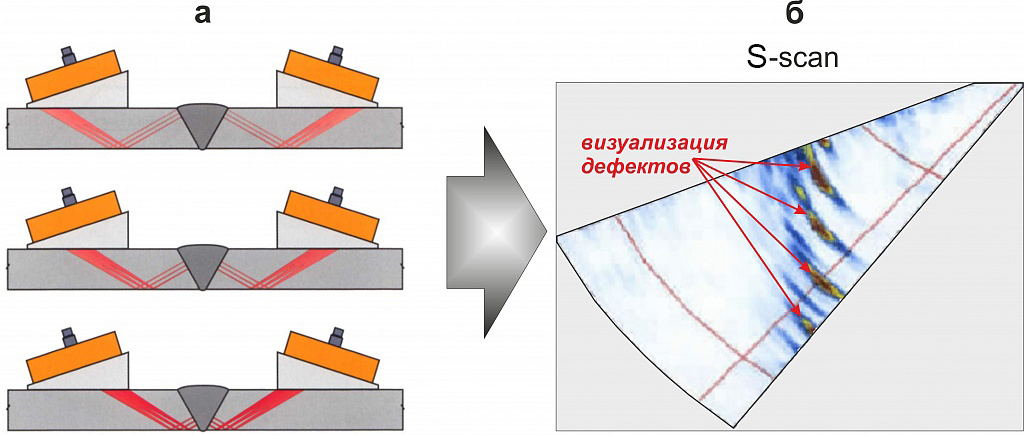
Анализ результатов, полученных с помощью RNN-декодера

 org/10.1371/journal.pcbi.1006822.g004
org/10.1371/journal.pcbi.1006822.g004 Такого отношения можно было бы ожидать, если бы границы функционировали как удлиненный пространственный сигнал, используемый животными для обновления их представления о своем местоположении относительно его поверхности. Соответственно, мы обнаружили, что для декодирования RNN на основе нейронов CA1 точность декодирования, ортогональная границам окружающей среды, возрастала по мере приближения к этой границе (Рис. 4d, Порядок рангов Спирмена между ошибкой и расстоянием до стены в области до 25 см от стены, г = 0.31, p ≪ 0,001, dof = 3968). Результат также сохраняется для x ( r = 0,35, p ≪ 0,001, dof = 2101) и r ( r = 0,25, p ≪ 0,001, dof = 1855) координаты отдельно. И наоборот, ошибка декодирования, параллельная границе, не модулировалась близостью.
Такого отношения можно было бы ожидать, если бы границы функционировали как удлиненный пространственный сигнал, используемый животными для обновления их представления о своем местоположении относительно его поверхности. Соответственно, мы обнаружили, что для декодирования RNN на основе нейронов CA1 точность декодирования, ортогональная границам окружающей среды, возрастала по мере приближения к этой границе (Рис. 4d, Порядок рангов Спирмена между ошибкой и расстоянием до стены в области до 25 см от стены, г = 0.31, p ≪ 0,001, dof = 3968). Результат также сохраняется для x ( r = 0,35, p ≪ 0,001, dof = 2101) и r ( r = 0,25, p ≪ 0,001, dof = 1855) координаты отдельно. И наоборот, ошибка декодирования, параллельная границе, не модулировалась близостью. Средняя ошибка прогноза для скоростей ниже 0,5 см / с составляет 16,5 см, что выше средней ошибки 12,1 см для всех скоростей выше 0,5 см / с (двусторонний t-критерий Велча, t = 10,62, p ≪ 0,001 , медианные ошибки 8,68 см и 7,74 см соответственно). Кажется правдоподобным, что более низкая точность предсказания во время стационарных периодов может быть связана с тем, что в эти периоды клетки преимущественно воспроизводят нелокальные траектории [38]. Второе интересное наблюдение заключается в том, что ошибка прогнозирования не увеличивается при более высоких скоростях (двусторонний t-критерий Велча между ошибками в точках данных, где скорость находится в диапазоне от 0.От 5 см / с до 10,5 см / с и ошибки в точках данных со скоростью выше 10,5 см / с, t = 0,31, p = 0,76).
Средняя ошибка прогноза для скоростей ниже 0,5 см / с составляет 16,5 см, что выше средней ошибки 12,1 см для всех скоростей выше 0,5 см / с (двусторонний t-критерий Велча, t = 10,62, p ≪ 0,001 , медианные ошибки 8,68 см и 7,74 см соответственно). Кажется правдоподобным, что более низкая точность предсказания во время стационарных периодов может быть связана с тем, что в эти периоды клетки преимущественно воспроизводят нелокальные траектории [38]. Второе интересное наблюдение заключается в том, что ошибка прогнозирования не увеличивается при более высоких скоростях (двусторонний t-критерий Велча между ошибками в точках данных, где скорость находится в диапазоне от 0.От 5 см / с до 10,5 см / с и ошибки в точках данных со скоростью выше 10,5 см / с, t = 0,31, p = 0,76). Анализ чувствительности
 Таким образом, биологически актуальный вопрос заключается в том, как такая информация распределяется между нейронами в пространстве и времени. Короче говоря, мы спросили, какие особенности нейрональной активности наиболее информативны при прогнозировании положения животного.С этой целью мы провели два различных типа анализа чувствительности для измерения устойчивости к разным типам возмущений. Для визуализации представлений, изученных RNN, см. Анализ уменьшения размерности (с использованием t-SNE) в S1 Text, S2 и S3 Figs.
Таким образом, биологически актуальный вопрос заключается в том, как такая информация распределяется между нейронами в пространстве и времени. Короче говоря, мы спросили, какие особенности нейрональной активности наиболее информативны при прогнозировании положения животного.С этой целью мы провели два различных типа анализа чувствительности для измерения устойчивости к разным типам возмущений. Для визуализации представлений, изученных RNN, см. Анализ уменьшения размерности (с использованием t-SNE) в S1 Text, S2 и S3 Figs. Нокаут-подход.

 Нейрон №55 имел частоту срабатывания в 4 раза выше, чем любой другой нейрон, что означает, что его удаление исключает наибольшее количество всплесков из анализа.Другие 4 наиболее влиятельных нейрона, по-видимому, являются типичными пирамидальными клетками места, характеризующимися чистыми полями места [2]. Выключение этих верхних нейронов привело к значительному снижению (> 1 см ) точности прогноза.
Нейрон №55 имел частоту срабатывания в 4 раза выше, чем любой другой нейрон, что означает, что его удаление исключает наибольшее количество всплесков из анализа.Другие 4 наиболее влиятельных нейрона, по-видимому, являются типичными пирамидальными клетками места, характеризующимися чистыми полями места [2]. Выключение этих верхних нейронов привело к значительному снижению (> 1 см ) точности прогноза. Среди этих менее влиятельных нейронов мы обнаружили как предполагаемые тормозящие интернейроны, так и пирамидные клетки без четких полей места и со скоростью возбуждения ниже средней. Например, карта скорости наименее влиятельного нейрона характеризовалась низкой частотой активации № 9 (рис. 5f). Как предполагают наиболее и наименее влиятельные нейроны, важность согласно анализу нокаута сильно коррелировала с частотой активации (порядок рангов Спирмена, r = 0,50, p val <0.001, dof = 61).
Среди этих менее влиятельных нейронов мы обнаружили как предполагаемые тормозящие интернейроны, так и пирамидные клетки без четких полей места и со скоростью возбуждения ниже средней. Например, карта скорости наименее влиятельного нейрона характеризовалась низкой частотой активации № 9 (рис. 5f). Как предполагают наиболее и наименее влиятельные нейроны, важность согласно анализу нокаута сильно коррелировала с частотой активации (порядок рангов Спирмена, r = 0,50, p val <0.001, dof = 61). Градиенты относительно ввода.
 Этот тип анализа чувствительности сильно отличается от анализа нокаута — чувствительность к нокауту измеряет влияние подавления нейрона, градиентная чувствительность измеряет влияние активности нейронов, отклоняющейся от ожидаемого значения.
Этот тип анализа чувствительности сильно отличается от анализа нокаута — чувствительность к нокауту измеряет влияние подавления нейрона, градиентная чувствительность измеряет влияние активности нейронов, отклоняющейся от ожидаемого значения. Подобно нокаут-анализу, это показало, насколько нейрон важен для прогноза. Два показателя чувствительности (нокаут и градиент) сильно коррелировали (порядок рангов Спирмена, ρ = 0,57, p ≪ 0,001, dof = 61), но не эквивалентны. Тесты оценили некоторые нейроны по-разному. Например, высокоактивный тормозной нейрон №55, который наиболее сильно влияет на точность согласно анализу нокаута, занимает 47-е место из 63 нейронов в анализе градиентной чувствительности.Таким образом, демонстрируя, что, несмотря на тот факт, что обе меры в целом совпадают, градиентный и нокаутный анализы охватывают различные понятия устойчивости по отношению к входным возмущениям. Интересно, что ни одна из двух мер чувствительности не коррелировала с теоретической мерой пространственной информации, предложенной Скаггсом и др. [39] (Порядок рангов Спирмена, градиент-против-Скэггс: ρ = -0,22, pval = 0,08, dof = 61; нок-против-Скэггс: ρ = -0,09, p = 0.
Подобно нокаут-анализу, это показало, насколько нейрон важен для прогноза. Два показателя чувствительности (нокаут и градиент) сильно коррелировали (порядок рангов Спирмена, ρ = 0,57, p ≪ 0,001, dof = 61), но не эквивалентны. Тесты оценили некоторые нейроны по-разному. Например, высокоактивный тормозной нейрон №55, который наиболее сильно влияет на точность согласно анализу нокаута, занимает 47-е место из 63 нейронов в анализе градиентной чувствительности.Таким образом, демонстрируя, что, несмотря на тот факт, что обе меры в целом совпадают, градиентный и нокаутный анализы охватывают различные понятия устойчивости по отношению к входным возмущениям. Интересно, что ни одна из двух мер чувствительности не коррелировала с теоретической мерой пространственной информации, предложенной Скаггсом и др. [39] (Порядок рангов Спирмена, градиент-против-Скэггс: ρ = -0,22, pval = 0,08, dof = 61; нок-против-Скэггс: ρ = -0,09, p = 0. 48, dof = 61). Это предполагает, что информационная оценка Скэггса отражает определенный аспект влияния каждого нейрона в контексте популяции клеток места. Предлагаемые нами меры дополняют информационный рейтинг Скэггса и потенциально раскрывают различные понятия чувствительности.
48, dof = 61). Это предполагает, что информационная оценка Скэггса отражает определенный аспект влияния каждого нейрона в контексте популяции клеток места. Предлагаемые нами меры дополняют информационный рейтинг Скэггса и потенциально раскрывают различные понятия чувствительности. Подраздел «Меры чувствительности» в разделе «Методы»). Мы видели, что чувствительность уменьшается при увеличении скорости стрельбы (рис. 6).Следовательно, это указывает на то, что при максимальной скорости стрельбы — например, вблизи центра поля стрельбы — небольшие изменения скорости стрельбы менее важны, чем по направлению к краям поля стрельбы. В целом это согласуется с теоретическими соображениями, которые указывают на то, что, как правило, нейронные ответы наиболее информативны в тех областях их кодового пространства, где частота активации изменяется наиболее быстро для данного изменения кодируемой переменной [40]. В случае ячеек места это соответствует краям поля места.И наоборот, за пределами поля места, где частота срабатывания падает близко к 0 Гц, чувствительность RNN к нейрону снова немного ниже (рис. 6).
Подраздел «Меры чувствительности» в разделе «Методы»). Мы видели, что чувствительность уменьшается при увеличении скорости стрельбы (рис. 6).Следовательно, это указывает на то, что при максимальной скорости стрельбы — например, вблизи центра поля стрельбы — небольшие изменения скорости стрельбы менее важны, чем по направлению к краям поля стрельбы. В целом это согласуется с теоретическими соображениями, которые указывают на то, что, как правило, нейронные ответы наиболее информативны в тех областях их кодового пространства, где частота активации изменяется наиболее быстро для данного изменения кодируемой переменной [40]. В случае ячеек места это соответствует краям поля места.И наоборот, за пределами поля места, где частота срабатывания падает близко к 0 Гц, чувствительность RNN к нейрону снова немного ниже (рис. 6).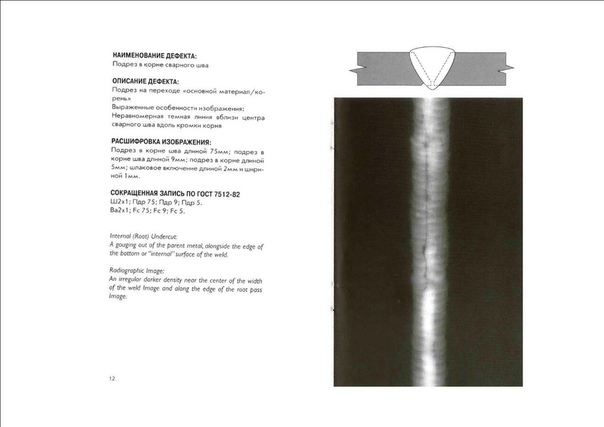 (c) Нормализованная чувствительность как функция нормализованной активности нейронов.
(c) Нормализованная чувствительность как функция нормализованной активности нейронов. Обсуждение
 декодер, включающий априорные значения, основанные на поведении животных и недавней истории пиков [14].
декодер, включающий априорные значения, основанные на поведении животных и недавней истории пиков [14]. В частности, при использовании более коротких временных окон счетчики всплесков становятся более шумными, и точность прогнозов байесовских моделей быстро ухудшается. В отличие от этого, декодер RNN был более устойчив к изменчивости подсчета всплесков, вероятно, из-за его способности объединять информацию по всей последовательности прошлых входов.Точно так же в ситуациях, когда было доступно меньше нейронов и, следовательно, общий объем информации был уменьшен, RNN демонстрировала явное преимущество перед байесовскими декодерами. Точно так же в задаче 1D преимущество RNN было наиболее очевидным для животного R2217, у которого было наименьшее количество зарегистрированных нейронов. Тем не менее обратите внимание, что меньшее количество зарегистрированных нейронов не обязательно означает более низкую точность. Как описано в Разделе 2.3.1, ошибка сильно зависит от количества доступных обучающих данных (продолжительности записи) и качества ячеек (количества и места срабатывания).Взятые вместе, эти результаты показывают, что декодирование нейронных данных с помощью RNN может оказаться особенно полезным в ситуациях, когда большие популяции нейронов недоступны или их сложно поддерживать стабильно.
В частности, при использовании более коротких временных окон счетчики всплесков становятся более шумными, и точность прогнозов байесовских моделей быстро ухудшается. В отличие от этого, декодер RNN был более устойчив к изменчивости подсчета всплесков, вероятно, из-за его способности объединять информацию по всей последовательности прошлых входов.Точно так же в ситуациях, когда было доступно меньше нейронов и, следовательно, общий объем информации был уменьшен, RNN демонстрировала явное преимущество перед байесовскими декодерами. Точно так же в задаче 1D преимущество RNN было наиболее очевидным для животного R2217, у которого было наименьшее количество зарегистрированных нейронов. Тем не менее обратите внимание, что меньшее количество зарегистрированных нейронов не обязательно означает более низкую точность. Как описано в Разделе 2.3.1, ошибка сильно зависит от количества доступных обучающих данных (продолжительности записи) и качества ячеек (количества и места срабатывания).Взятые вместе, эти результаты показывают, что декодирование нейронных данных с помощью RNN может оказаться особенно полезным в ситуациях, когда большие популяции нейронов недоступны или их сложно поддерживать стабильно.
 Наличие доступа к градиентам по каждому счету спайков позволяет ставить новые вопросы о динамической изменчивости информационного содержания отдельных нейронов.
Наличие доступа к градиентам по каждому счету спайков позволяет ставить новые вопросы о динамической изменчивости информационного содержания отдельных нейронов. Материалы и методы
Заявление об этике
Сбор данных
Животные и хирургия.
 2 мм , AP: 3,8 мм кзади от Bregma) и левой медиальной энторинальной коры (MEC) (ML = 4,5 мм , AP = 0,3-0,7 кпереди от поперечного синуса, под углом 8-10 °). Провода были покрыты платиной для уменьшения импеданса до 200-300 кОм при 1 кГц . После того, как крысы оправились от операции, их поддерживали на уровне 90% веса при свободном кормлении с доступом к воде ad libitum и содержали индивидуально в течение 12 — часов с циклом свет / темнота.Данные MEC не анализировались для этого исследования.
2 мм , AP: 3,8 мм кзади от Bregma) и левой медиальной энторинальной коры (MEC) (ML = 4,5 мм , AP = 0,3-0,7 кпереди от поперечного синуса, под углом 8-10 °). Провода были покрыты платиной для уменьшения импеданса до 200-300 кОм при 1 кГц . После того, как крысы оправились от операции, их поддерживали на уровне 90% веса при свободном кормлении с доступом к воде ad libitum и содержали индивидуально в течение 12 — часов с циклом свет / темнота.Данные MEC не анализировались для этого исследования. Запись.
 Тетроды постепенно продвигались с шагом 62,5, мкм, в течение дней, пока не были идентифицированы клетки места (CA1) и клетки сетки (MEC).
Тетроды постепенно продвигались с шагом 62,5, мкм, в течение дней, пока не были идентифицированы клетки места (CA1) и клетки сетки (MEC). Экспериментальная аппаратура и протокол.
 Для других животных (R2336, R2337) записи были сделаны с первого дня воздействия задачи Z-track.Эти записи составляют набор данных, который мы называем задачей 1D-декодирования.
Для других животных (R2336, R2337) записи были сделаны с первого дня воздействия задачи Z-track.Эти записи составляют набор данных, который мы называем задачей 1D-декодирования. Декодер на основе рекуррентных нейронных сетей
 В этой работе нас интересует обучение нейронной сети для декодирования пространственных координат крысы на основе активности, записанной с ее клеток гиппокампа.
В этой работе нас интересует обучение нейронной сети для декодирования пространственных координат крысы на основе активности, записанной с ее клеток гиппокампа. Расширенные реализации рекуррентных сетей, такие как долговременная память (LSTM) [34] и закрытые повторяющиеся блоки (GRU) [42, 43], имеют особую архитектуру и наборы параметров, которые контролируют, в какой степени прошлые действия должны быть запомнены или перезаписаны. по новому вводу [43]. Это дает им возможность объединять знания в более длительной последовательности.Благодаря использованию прошлых входных данных в качестве контекстной информации эти сети достигли выдающейся производительности с зашумленными последовательными данными, такими как текст и речь.
Расширенные реализации рекуррентных сетей, такие как долговременная память (LSTM) [34] и закрытые повторяющиеся блоки (GRU) [42, 43], имеют особую архитектуру и наборы параметров, которые контролируют, в какой степени прошлые действия должны быть запомнены или перезаписаны. по новому вводу [43]. Это дает им возможность объединять знания в более длительной последовательности.Благодаря использованию прошлых входных данных в качестве контекстной информации эти сети достигли выдающейся производительности с зашумленными последовательными данными, такими как текст и речь. Сетевая архитектура.

 Сеть производит прогноз для координат x и y только в конце последовательности, при t = 100.
Сеть производит прогноз для координат x и y только в конце последовательности, при t = 100. Извлечение признаков.
Порядок обучения РНС.
Поиск модели.
Байесовский декодер
Перекрестная проверка и усреднение результатов
Анализ результатов декодирования
Количественная оценка ошибок прогнозирования.
Меры чувствительности.
Вспомогательная информация
S1 Рис. Средняя ошибка прогноза для различных мгновенных скоростей движения.
S2 Рис. T-SNE анализ.
S3 Рис. T-SNE анализ.
S4 Рис. Градиентный анализ.
Благодарности
Ссылки
Декодирование дисциплин — улучшение обучения студентов
Узнать больше
Многомасштабные коды с исправлением ошибок и их декодирование с использованием распространения убеждений
Аннотация
Декодер Рида-Соломона — MATLAB rsdec
Syntax
decoded = rsdec (code, n, k)
decoded = rsdec (code, n, k, genpoly)
decoded = rsdec (..., paritypos )
[декодировано, cnumerr] = rsdec (...)
[декодировано, cnumerr, ccode] = rsdec (...)
Описание
декодировано = rsdec (code, n, k) попытки
для декодирования принятого сигнала в коде с использованием
[ n , k ] Декодирование Рида-Соломона
процесс с полиномом генератора узкого смысла. код есть
Галуа
массив символов по m бит каждый. Каждый n -элемент
строка кода представляет собой искаженное систематическое кодовое слово,
где символы четности находятся в конце, а крайний левый символ —
самый значимый символ. n составляет не более 2 м -1.
Если n не точно 2 m -1, rsdec предполагает
что код является поврежденной версией сокращенного
код., декодированном , каждая строка представляет
попытка декодирования соответствующей строки в коде .
Ошибка декодирования происходит, если rsdec обнаруживает
более (n-k) / 2 ошибок в строке кода .
В этом случае rsdec формирует соответствующую строку
из декодировано путем простого удаления n-k символов
с конца строки код . декодировано = rsdec (code, n, k, genpoly) — это
то же, что и синтаксис выше, за исключением того, что непустое значение genpoly указывает
порождающий полином для кода. В этом случае genpoly — это
вектор-строка Галуа, в котором перечислены коэффициенты в порядке убывания
мощности порождающего полинома. Образующий полином должен
имеют степень н-к . Чтобы использовать значение по умолчанию в узком смысле
генератор полином, установите genpoly на [] . декодировано = rsdec (..., указывает, были ли добавлены символы четности в коде paritypos ) или
добавляется к сообщению в операции кодирования. паритетных позиций может быть 'конец' или 'начало' . По умолчанию "конец" . Если paritypos 'начало' , сбой декодирования вызывает rsdec чтобы удалить n-k символов с начала, а не с конца
ряд. [декодировано, cnumerr] = rsdec (...) возвращает
вектор-столбец cnumerr , каждый элемент которого
— количество исправленных ошибок в соответствующей строке кода .
Значение -1 в cnumerr указывает
ошибка декодирования в этой строке в коде . [декодировано, cnumerr, ccode] = rsdec (...) возвращает ccode ,
исправленная версия код . Массив Галуа ccode имеет
тот же формат, что и , код .Если ошибка декодирования
встречается в определенной строке кода , соответствующий
строка в коде ccode содержит эту строку без изменений. Самый быстрый способ обучения основной стратегии декодирования
[Транскрипт самого быстрого способа обучения основной стратегии декодирования]
Испытание основной стратегии декодирования со все более сложными словами
Посмотрите, как далеко он зашел
CVC Уровень фонематической сложности
CVCC Уровень фонематической сложности
CCVC Уровень фонематической сложности
CCVCC Уровень фонематической сложности
Что насчет звуковых нарушений?
Затягиваются проблемы смешивания
С какими проблемами смешивания вы столкнулись? Пожалуйста, ответьте в комментариях ниже!
.